podmanを使ってOracle Database FreeとOracle REST Data Servicesをコンテナとして実行する
Containerized APEX Development Environment
https://github.com/United-Codes/uc-local-apex-dev
Qwen3 30B A3B MLXをMacのLM Studioで実行しAPEXアプリケーションからツール呼び出しを行う
https://github.com/ujnak/apexapps/blob/master/exports/chat-with-generative-ai-hc-242.zip
https://apexugj.blogspot.com/2025/01/deepseek-r1-novel-generator.html
% brew tap microsoft/foundrylocal
==> Tapping microsoft/foundrylocal
Cloning into '/opt/homebrew/Library/Taps/microsoft/homebrew-foundrylocal'...
remote: Enumerating objects: 126, done.
remote: Counting objects: 100% (22/22), done.
remote: Compressing objects: 100% (14/14), done.
remote: Total 126 (delta 12), reused 8 (delta 8), pack-reused 104 (from 1)
Receiving objects: 100% (126/126), 313.79 KiB | 1.92 MiB/s, done.
Resolving deltas: 100% (65/65), done.
Tapped 2 formulae (17 files, 335.2KB).
%
% brew install foundrylocal
==> Downloading https://formulae.brew.sh/api/formula.jws.json
==> Downloading https://formulae.brew.sh/api/cask.jws.json
==> Fetching microsoft/foundrylocal/foundrylocal
==> Downloading https://github.com/microsoft/Foundry-Local/releases/download/v0.3.9267/FoundryLocal-osx-arm64-0.3.9267.42993.zip
==> Downloading from https://objects.githubusercontent.com/github-production-release-asset-2e65be/958239663/158c7cec-ee9a-4694-a3b7-cb3091759f6c?X-Amz-Al
################################################################################################################################################## 100.0%
==> Installing foundrylocal from microsoft/foundrylocal
🍺 /opt/homebrew/Cellar/foundrylocal/0.3.9267.42993: 9 files, 75.6MB, built in 1 second
==> Running `brew cleanup foundrylocal`...
Disable this behaviour by setting HOMEBREW_NO_INSTALL_CLEANUP.
Hide these hints with HOMEBREW_NO_ENV_HINTS (see `man brew`).
%
% foundry model list
Alias Device Task File Size License Model ID
-----------------------------------------------------------------------------------------------
phi-4 GPU chat-completion 8.37 GB MIT Phi-4-generic-gpu
CPU chat-completion 10.16 GB MIT Phi-4-generic-cpu
--------------------------------------------------------------------------------------------------------
mistral-7b-v0.2 GPU chat-completion 4.07 GB apache-2.0 mistralai-Mistral-7B-Instruct-v0-2-generic-gpu
CPU chat-completion 4.07 GB apache-2.0 mistralai-Mistral-7B-Instruct-v0-2-generic-cpu
-------------------------------------------------------------------------------------------------------------------------------------
phi-3.5-mini GPU chat-completion 2.16 GB MIT Phi-3.5-mini-instruct-generic-gpu
CPU chat-completion 2.53 GB MIT Phi-3.5-mini-instruct-generic-cpu
------------------------------------------------------------------------------------------------------------------------
phi-3-mini-128k GPU chat-completion 2.13 GB MIT Phi-3-mini-128k-instruct-generic-gpu
CPU chat-completion 2.54 GB MIT Phi-3-mini-128k-instruct-generic-cpu
---------------------------------------------------------------------------------------------------------------------------
phi-3-mini-4k GPU chat-completion 2.13 GB MIT Phi-3-mini-4k-instruct-generic-gpu
CPU chat-completion 2.53 GB MIT Phi-3-mini-4k-instruct-generic-cpu
-------------------------------------------------------------------------------------------------------------------------
phi-4-mini-reasoning GPU chat-completion 3.15 GB MIT Phi-4-mini-reasoning-generic-gpu
CPU chat-completion 4.52 GB MIT Phi-4-mini-reasoning-generic-cpu
-----------------------------------------------------------------------------------------------------------------------
deepseek-r1-14b GPU chat-completion 10.27 GB MIT deepseek-r1-distill-qwen-14b-generic-gpu
-------------------------------------------------------------------------------------------------------------------------------
deepseek-r1-7b GPU chat-completion 5.58 GB MIT deepseek-r1-distill-qwen-7b-generic-gpu
------------------------------------------------------------------------------------------------------------------------------
phi-4-mini GPU chat-completion 3.72 GB MIT Phi-4-mini-instruct-generic-gpu
----------------------------------------------------------------------------------------------------------------------
qwen2.5-0.5b GPU chat-completion 0.68 GB apache-2.0 qwen2.5-0.5b-instruct-generic-gpu
CPU chat-completion 0.80 GB apache-2.0 qwen2.5-0.5b-instruct-generic-cpu
------------------------------------------------------------------------------------------------------------------------
qwen2.5-coder-0.5b GPU chat-completion 0.52 GB apache-2.0 qwen2.5-coder-0.5b-instruct-generic-gpu
CPU chat-completion 0.80 GB apache-2.0 qwen2.5-coder-0.5b-instruct-generic-cpu
------------------------------------------------------------------------------------------------------------------------------
qwen2.5-1.5b GPU chat-completion 1.51 GB apache-2.0 qwen2.5-1.5b-instruct-generic-gpu
CPU chat-completion 1.78 GB apache-2.0 qwen2.5-1.5b-instruct-generic-cpu
------------------------------------------------------------------------------------------------------------------------
qwen2.5-7b GPU chat-completion 5.20 GB apache-2.0 qwen2.5-7b-instruct-generic-gpu
CPU chat-completion 6.16 GB apache-2.0 qwen2.5-7b-instruct-generic-cpu
----------------------------------------------------------------------------------------------------------------------
qwen2.5-coder-1.5b GPU chat-completion 1.25 GB apache-2.0 qwen2.5-coder-1.5b-instruct-generic-gpu
CPU chat-completion 1.78 GB apache-2.0 qwen2.5-coder-1.5b-instruct-generic-cpu
------------------------------------------------------------------------------------------------------------------------------
qwen2.5-coder-7b GPU chat-completion 4.73 GB apache-2.0 qwen2.5-coder-7b-instruct-generic-gpu
CPU chat-completion 6.16 GB apache-2.0 qwen2.5-coder-7b-instruct-generic-cpu
----------------------------------------------------------------------------------------------------------------------------
qwen2.5-14b GPU chat-completion 9.30 GB apache-2.0 qwen2.5-14b-instruct-generic-gpu
CPU chat-completion 11.06 GB apache-2.0 qwen2.5-14b-instruct-generic-cpu
-----------------------------------------------------------------------------------------------------------------------
qwen2.5-coder-14b GPU chat-completion 8.79 GB apache-2.0 qwen2.5-coder-14b-instruct-generic-gpu
CPU chat-completion 11.06 GB apache-2.0 qwen2.5-coder-14b-instruct-generic-cpu
%
今の所、利用できるモデルは、Phi(Microsoft - 米国)、Mistral(Mistral AI - フランス)、DeepSeek-R1(DeepSeek - 中国)、Qwen2.5(アリババ - 中国)のようです。
foundry model run phi-4
% foundry model run phi-4
Downloading model...
[####################################] 100.00 % [Time remaining: about 0s] 29.3 MB/s
🕚 Loading model...
🟢 Model Phi-4-generic-gpu loaded successfully
Interactive Chat. Enter /? or /help for help.
Interactive mode, please enter your prompt
> /exit
%
% foundry model run phi-4 --interactive false
Model phi-4 was found in the local cache.
Interactive Chat. Enter /? or /help for help.
Interactive mode, please enter your prompt
>
foundry model load phi-4
% foundry model load phi-4
🕓 Loading model...
🟢 Model phi-4 loaded successfully
%
% foundry model load phi-4
🕛 Loading model... Exception: Failed: Loading model phi-4 from http://localhost:5273/openai/load/Phi-4-generic-gpu?ttl=600&ep=webgpu
Bad Request
Failed loading model Phi-4-generic-gpu
Model was not found locally. Please run 'foundry model download <model name>'.
%
foundry model download phi-4
% foundry model download phi-4
Downloading model...
[####################################] 100.00 % [Time remaining: about 0s] 31.0 MB/s
Tips:
- To find model cache location use: foundry cache location
- To find models already downloaded use: foundry cache ls
% foundry cache ls
Models cached on device:
Alias Model ID
💾 phi-4 Phi-4-generic-gpu
%
TTLのデフォルトは600、つまり未使用状態が10分続くとモデルはアンロードされます。TTLを延長するには、--ttlオプションに秒数を与えます。
foundry model load phi-4 --ttl 3600
% foundry model load phi-4 --ttl 3600
🕓 Loading model...
🟢 Model phi-4 loaded successfully
%
% foundry model run deepseek-r1-14b
Model deepseek-r1-14b was found in the local cache.
Unloading existing models. Use --retain true to keep additional models loaded.
🕔 Loading model...
🟢 Model deepseek-r1-distill-qwen-14b-generic-gpu loaded successfully
Interactive Chat. Enter /? or /help for help.
Interactive mode, please enter your prompt
> /exit
% foundry service ps
Models running in service:
Alias Model ID
🟢 deepseek-r1-14b deepseek-r1-distill-qwen-14b-generic-gpu
%
% foundry model unload deepseek-r1-14b
Exception: Failed: Unloading model deepseek-r1-14b
Bad Request
Failed unloading model deepseek-r1-14b
Model was not found locally. Please run 'foundry model download <model name>'.
% foundry model unload deepseek-r1-distill-qwen-14b-generic-gpu
Model deepseek-r1-distill-qwen-14b-generic-gpu was unloaded
ynakakoshi@Ns-Macbook ~ %
% foundry service ps
Models running in service:
Alias Model ID
🟢 phi-4 Phi-4-generic-gpu
%
foundry service status
% foundry service status
🟢 Model management service is running on http://localhost:5273/openai/status
%
Foundry Localがサービスを待ち受けるサービスURLのポートは固定ではありません。Microsoftから提供されているFoundry Local SDKでは、FoundryLocaclManagerというクラスが提供されていて、そのクラスからFoundry LocalのサービスURLを取得することができます。APEXからFoundry Localを呼び出す場合はSDKが使えないため、必ずサービスURLを確認してアプリケーションに設定する必要があります。
ツール呼び出しの確認
日本の人口を取得するために、WKSP_APEXDEVスキーマ内の関連するテーブルをクエリする必要があります。通常、人口データは「COUNTRIES」テーブルに格納されています。以下は、日本の人口を取得するためのSQL SELECT文です: ```sql SELECT POPULATION FROM WKSP_APEXDEV.COUNTRIES WHERE COUNTRY_NAME = 'Japan'; ``` このクエリは、国名が「Japan」であるレコードの人口を取得します。質問の回答にはなっていますが、ツール呼び出しが行われていません。

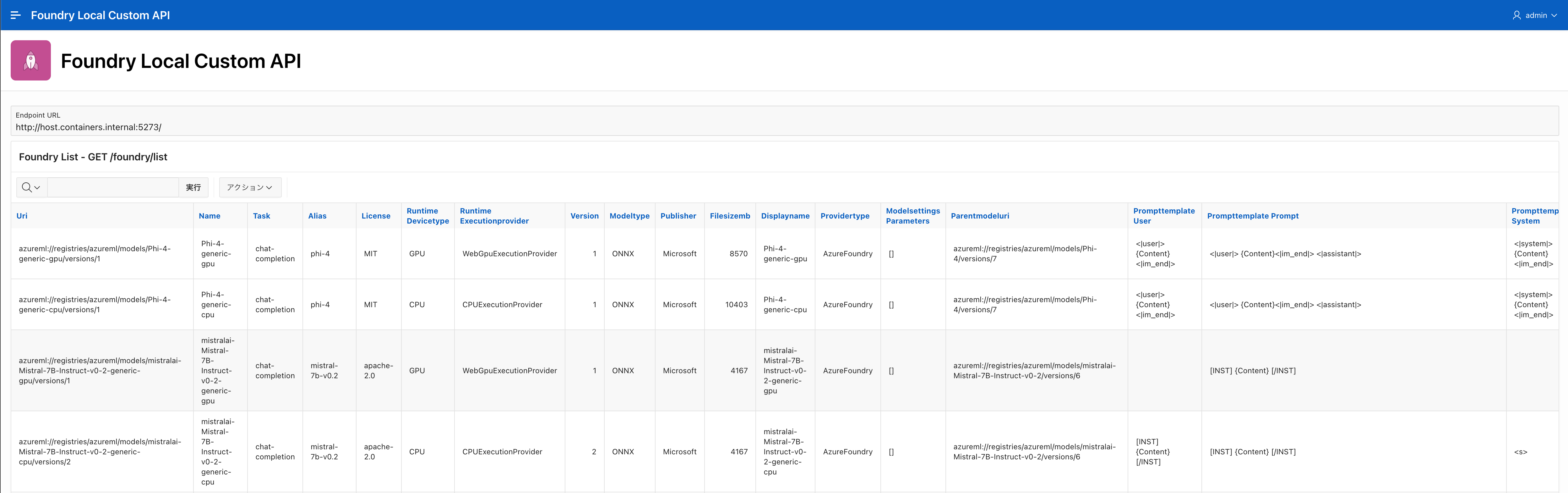
curl http://localhost:5273/foundry/list | jq -r '.[] | [.name, .maxOutputTokens, .supportsToolCalling ] | @tsv' | column -t
% curl http://localhost:5273/foundry/list | jq -r '.[] | [.name, .maxOutputTokens, .supportsToolCalling ] | @tsv' | column -t
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 38716 100 38716 0 0 26890 0 0:00:01 0:00:01 --:--:-- 26886
Phi-4-generic-gpu 2048 false
Phi-4-generic-cpu 2048 false
mistralai-Mistral-7B-Instruct-v0-2-generic-gpu 2048 false
mistralai-Mistral-7B-Instruct-v0-2-generic-cpu 2048 false
Phi-3.5-mini-instruct-generic-gpu 2048 false
Phi-3.5-mini-instruct-generic-cpu 2048 false
Phi-3-mini-128k-instruct-generic-gpu 2048 false
Phi-3-mini-128k-instruct-generic-cpu 2048 false
Phi-3-mini-4k-instruct-generic-gpu 2048 false
Phi-3-mini-4k-instruct-generic-cpu 2048 false
Phi-4-mini-reasoning-generic-gpu 2048 false
Phi-4-mini-reasoning-generic-cpu 2048 false
deepseek-r1-distill-qwen-14b-generic-gpu 2048 false
deepseek-r1-distill-qwen-7b-generic-gpu 2048 false
Phi-4-mini-instruct-generic-gpu 2048 false
qwen2.5-0.5b-instruct-generic-gpu 2048 false
qwen2.5-0.5b-instruct-generic-cpu 2048 false
qwen2.5-coder-0.5b-instruct-generic-gpu 2048 false
qwen2.5-coder-0.5b-instruct-generic-cpu 2048 false
qwen2.5-1.5b-instruct-generic-gpu 2048 false
qwen2.5-1.5b-instruct-generic-cpu 2048 false
qwen2.5-7b-instruct-generic-gpu 2048 false
qwen2.5-7b-instruct-generic-cpu 2048 false
qwen2.5-coder-1.5b-instruct-generic-gpu 2048 false
qwen2.5-coder-1.5b-instruct-generic-cpu 2048 false
qwen2.5-coder-7b-instruct-generic-gpu 2048 false
qwen2.5-coder-7b-instruct-generic-cpu 2048 false
qwen2.5-14b-instruct-generic-gpu 2048 false
qwen2.5-14b-instruct-generic-cpu 2048 false
qwen2.5-coder-14b-instruct-generic-gpu 2048 false
qwen2.5-coder-14b-instruct-generic-cpu 2048 false
%
ストリーム出力の確認

カスタムAPI