Oracle APEX 24.2に、AIに問い合わせてデータ・モデルを作成する機能が追加されました。この機能の動作確認を、最近話題のDeepSeek-R1を使って実施してみます。オンラインでAPIを呼び出す代わりに、LM Studioのローカル・サーバーにモデルをロードし、OpenAI互換のChat Completions APIで呼び出します。
Apple Macbook ProのM4 Max/128GBで動作する最大のモデルdeepseek-r1-distill-llama-70bを使います。性能は変わるとは思いますが、10GBメモリ以下で動かせるDeepSeek-R1の蒸留モデルもあるようです。
作業結果について、OpenAI GPT-4oとほとんど同じ回答が得られる印象です。ただし、すごい時間がかかる - これはモデルの問題というより、ローカルの環境が遅いから - また、処理時間での制限のため、エラーが発生して回答が得られないことがあります。Chat Completions APIはAPEX_WEB_SERVICE.MAKE_REST_REQUESTで呼び出していますが、その引数p_transfer_timeoutのデフォルト値が180秒のため、それ以上処理に時間がかかるとタイムアウトが発生するようです。
OpenAIのo1でも同様ですが、推論モデルは回答を生成するまでに比較的長い時間がかかります。また、Oracle APEXではデータベース・サーバーからリクエストを送信するため、ストリーミングを扱うことができません。結果として、問い合わせが難しいとAPIリクエストのタイムアウトが発生する可能性が高くなります。
以下より実際に行った作業を紹介します。
使用したLM Studioのバージョンは0.3.8です。
Discoverのアイコンをクリックして、Model Searchを開き、DeepSeek-R1を検索します。LM Studioを動かしているホストで実行可能なモデルをダウンロードします。
本記事ではmlx-community/DeepSeek-R1-Distill-Llama-70B-8bitを使用することにしました。MシリーズのMacでLM Studioを実行しているため、MLXフォーマットのモデルを優先しています。
Developerアイコンをクリックします。Settingsを開き、Server Portを設定します。本記事では8080にしています。他のモデルが自動的にロードされてメモリが不足しないように、Just-in-Time Model LoadingはOffにします。
Statusを切り替え、Runningにします。
Select a model to loadをクリックし、ダウンロード済みのモデルDeepSeek R1 Distill Llama 70Bをロードします。
Context Lengthに最大値の131072を設定し、Load Modelを実行します。
モデルのステータスがREADYになれば、APIから呼び出せます。
Oracle APEXの設定に移ります。Oracle APEX 24.2は同じMacのpodmanで動作しています。Oracle APEX環境の構築手順については、
こちらの記事で紹介しています。
Oracle APEXのワークスペースにサインインし、ワークスペース・ユーティリティの生成AIを開きます。
作成済みの生成AIサービスが一覧されます。作成をクリックします。
識別のAIプロバイダとしてOpenAIを選択します。名前はDeepSeek-R1 Distilled Llama 70Bとします。
ユーティリティのAIを使用したデータ・モデルの作成から呼び出せるように、アプリケーション・ビルダーで使用をオンにします。ベースURLは、コンテナで実行されているOracle Databaseから外の環境にアクセスするため、以下を指定します。
http://host.containers.internal:8080/v1
認証は不要ですが資格証明が必須項目であるため、設定だけは行います。
資格証明に
- 新規作成 -を選択し、
APIキーとして
適当な文字列を設定します。
AIモデルにdeepseek-r1-distill-llama-70bを設定します。
ここに設定するモデル名はLM Studioの
API Usageのセクションに、
This model's API identifierとして表示されています。
追加属性をクリックして開き、
JSON属性として以下を記述します。
{ "max_tokens": 131072 }
以上でダイアログを閉じます。
接続のテストをクリックして、
接続に成功することを確認します。
作成をクリックします。
以上で、生成AIサービスとしてDeepSeek-R1(の蒸留モデル)を呼び出せるようになりました。
SQLワークショップのユーティリティのAIを使用したデータ・モデルの作成を開きます。
APEXアシスタントのダイアログが開きます。SQL形式としてOracle SQLを選びます。
以下のメッセージを入力します。
国名、ISO3166-1 Alpha-2コード、首都名、首都の位置の経度と緯度を保存する表をEBAJ_COUNTRIESとして作成してください。日本語で会話してください。
Oracle APEXのプロンプトは英語なので(結果として英語と日本語が混在したメッセージがLLMに送信される)、回答が英語になることもあります。その点を考慮して、日本語で回答するように指示しています。
2分強の処理時間を費やした後、以下の回答が得られました。
生成されたSQLスクリプトは以下です。実行すると定義通りに表が作成されます。
-- create tables
create table ebaj_countries (
id number generated by default on null as identity
constraint ebaj_countries_pk primary key,
country_name varchar2(255) not null,
iso_code varchar2(2) not null
constraint ebaj_countries_iso_code_uk unique,
capital_name varchar2(255),
longitude number(9,6),
latitude number(9,6),
row_version integer not null,
created_on date not null,
created_by varchar2(255) not null,
updated_on date not null,
updated_by varchar2(255) not null )
/
-- triggers
create or replace trigger ebaj_countries_biu
before insert or update
on ebaj_countries
for each row
begin
:new.updated_on := sysdate;
:new.updated_by := coalesce(sys_context('APEX$SESSION','APP_USER'),user);
if inserting then
:new.row_version := 1;
:new.created_on := :new.updated_on;
:new.created_by := :new.updated_by;
elsif updating then
:new.row_version := nvl(:old.row_version, 0) + 1;
end if;
end ebaj_countries_biu;
/
今回の用途では、列ISO_CODEを主キーとして、監査列も行バージョンの列も不要です。これらの列は、Oracle APEXが生成するプロンプトで作成するよう指示されているため、SQLスクリプトに含まれています。
これらを削除します。
列ISO_CODEを主キーとして、列IDは削除してください。
3分弱考えて、以下の回答が返されました。
生成されたDDLは以下です。指示通りに列IDが削除され、列ISO_CODEが主キーになっています。
-- create tables
create table ebaj_countries (
iso_code varchar2(2) not null
constraint ebaj_countries_pk primary key,
country_name varchar2(255) not null,
capital_name varchar2(255),
longitude number(9,6),
latitude number(9,6),
row_version integer not null,
created_on date not null,
created_by varchar2(255) not null,
updated_on date not null,
updated_by varchar2(255) not null )
/
-- triggers
create or replace trigger ebaj_countries_biu
before insert or update
on ebaj_countries
for each row
begin
:new.updated_on := sysdate;
:new.updated_by := coalesce(sys_context('APEX$SESSION','APP_USER'),user);
if inserting then
:new.row_version := 1;
:new.created_on := :new.updated_on;
:new.created_by := :new.updated_by;
elsif updating then
:new.row_version := nvl(:old.row_version, 0) + 1;
end if;
end ebaj_countries_biu;
/
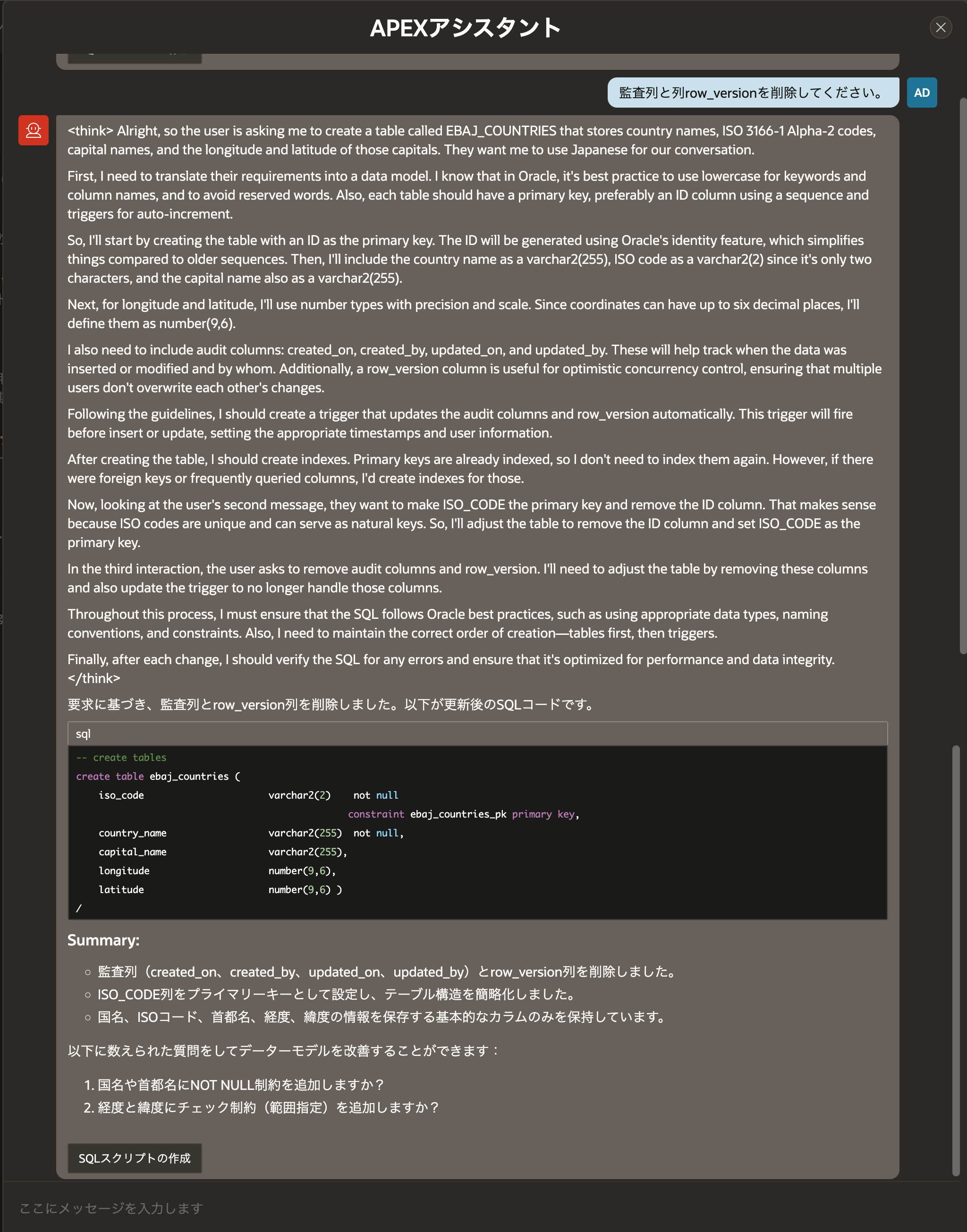
監査列と列ROW_VERSIONを削除します。
監査列と列row_versionを削除してください。
3分弱考えて、以下の回答が返されました。
生成されたDDLは以下です。監査列と列ROW_VERSIONが削除されています。監査列を正しく認識しているのもそうですが、トリガーも削除されています。
-- create tables
create table ebaj_countries (
iso_code varchar2(2) not null
constraint ebaj_countries_pk primary key,
country_name varchar2(255) not null,
capital_name varchar2(255),
longitude number(9,6),
latitude number(9,6) )
/
これで完成なので、SQLスクリプトの生成を実行します。
このまま継続してサンプル・データの生成まで行おうとすると、表を作成するDDLが保存されれずに、サンプル・データのINSERT文に置き換わることがありました。少なくとも、LM StudioとDeepSeek-R1を使う場合は、DDLの作成で終了した方が良さそうです。
スクリプト・エディタが開きます。
スクリプト名を入力し、実行します。
即時実行します。
表が作成されます。
ここからアプリケーションの作成を行うことで、AIによるデータ・モデルの作成からAPEXアプリケーションの作成まで、一気に実行できます。
今回の確認作業については、以上になります。
Oracle APEXからLM StudioにDDLを生成するように指示をしたときに、LM Studio(DeepSeek-R1)から、推論の経過が<think>...</think>で囲んで返されています。
最初の指示に対して、以下の推論をしています。
よし、Oracleデータベースに「EBAJ_COUNTRIES」という名前のテーブルを作成する必要があります。このテーブルは、国名、ISO3166-1 Alpha-2コード、首都名、およびその経度と緯度を格納します。要件を整理します。
まず、テーブルには次のカラムが必要です:国名、ISOコード、首都名、経度、緯度。ガイドラインに従い、テーブル名には「ebaj」というプレフィックスを付けます。
主キーは数値型のIDで、デフォルトで生成されるものとします。このカラム名を「id」とし、オートインクリメントにはアイデンティティを使用します。
国名と首都名は文字列なので、varchar2(255)型にします。一方、ISOコードは短い文字列なので、varchar2(2)型が適切です。
経度と緯度は数値型とし、小数点が必要なので精度を9、スケールを6に設定します。
監査用カラムとして、created_on、created_by、updated_on、updated_byを追加します。これらは、データがいつ、誰によって挿入または更新されたかを記録します。
また、行のバージョン管理のためにrow_versionカラムを追加します。これは初期値を1とし、行が更新されるたびにインクリメントされるようにします。
トリガーも作成し、挿入や更新の前にcreatedおよびupdatedのタイムスタンプやユーザーを設定するようにします。これにより、両方のケースに対応できます。
インデックスについては、外部キーのためのものが必要ですが、今回外部キーはないため、もしISOコードが頻繁に検索される場合にはiso_codeにインデックスを追加するのが良いでしょう。
次の指示では、以下の推論をしています。
よし、ユーザーからのSQLテーブル変更のリクエストに対応する必要があります。以前、ユーザーはebaj_countriesというテーブルを作成し、IDを主キーとした特定のカラムを含むよう求めていました。しかし、今回はIDカラムを削除し、代わりにISO_CODEを主キーにしたいというリクエストです。
まず、この変更の理由を理解する必要があります。ISO_CODEを主キーとして使用するのは理にかなっています。なぜなら、これは各国を一意に識別する固定値であり、クエリや結合を簡素化できるからです。また、IDカラムを削除するのは、冗長性を減らし、テーブル構造をシンプルに保つためかもしれません。
元のSQLコードを見ると、IDカラムは主キーとして定義されており、アイデンティティシーケンスを使用しています。このカラムを削除するには、IDカラムとその主キー制約を削除し、代わりにISO_CODEを主キーとして設定する必要があります。
次に、ISO_CODEカラムは現在一意制約(UNIQUE)が付いていますが、これを主キーに変更します。このためには、一意制約を主キー制約に変更し、正しくインデックスが設定されていることを確認します。
依存関係も考慮する必要があります。IDが削除されるため、このテーブル内ではIDを参照する外部キーがないので、その点は簡単です。ただし、他のテーブルがebaj_countries.idを参照している場合、その参照をISO_CODEに変更する必要があります。ただし、ユーザーが他のテーブルについて言及していないため、今回はこのテーブルに集中します。
テーブル作成スクリプトを調整し、IDカラムを削除してISO_CODEを主キーに設定します。その後、トリガーを確認します。このトリガーはIDカラムをrow_versionで参照していますが、待てよ……トリガーはテーブル構造に基づく:newと:oldを使用しているので、IDが削除されても問題ありません。row_versionはそのまま残っているので、トリガーは正常に動作するはずです。
次に、SQLコードを以下のように再構築します。IDカラムとその制約を削除し、ISO_CODEの制約を主キーに変更し、その他のカラムはそのままにします。トリガーについては、挿入や更新の前に動作するようになっており、IDカラムに直接依存していないので変更は不要です。
この変更の影響も考慮する必要があります。ISO_CODEが主キーになるため、必ずNOT NULLかつ一意(UNIQUE)である必要があります。これは元々の設定と一致しているので問題ありません。一意制約は主キー制約が代わりに適用されるため削除できます。
最後に、更新されたSQLコードを提示し、変更内容を説明します。IDを削除し、新しい主キーを設定したことを要約し、ユーザーのニーズに合致しているか、さらに調整が必要か確認するためのフォローアップ質問をします。
これで十分だと思います。更新されたコードは、ユーザーの要件を正確に反映するはずです。
最後の指示では、以下の推論をしています。
ユーザーがEBAJ_COUNTRIESというテーブルを作成してほしいと依頼しています。このテーブルには、国名、ISO 3166-1 Alpha-2コード、首都名、そしてその首都の経度と緯度を格納する必要があります。また、会話は日本語で進めてほしいとのことです。
まず、ユーザーの要件をデータモデルに変換する必要があります。Oracleでは、キーワードやカラム名は小文字を使用し、予約語を避けるのがベストプラクティスです。また、各テーブルには主キーを設定する必要があり、できればシーケンスやトリガーを使用したIDカラムを自動生成するのが望ましいです。
まず、IDを主キーとしたテーブルを作成します。IDはOracleのアイデンティティ機能を使用して生成します。この機能は、従来のシーケンスを使用する方法よりも簡単です。その後、国名をvarchar2(255)、ISOコードを2文字なのでvarchar2(2)、首都名もvarchar2(255)として追加します。
次に、経度と緯度については、精度とスケールを設定した数値型を使用します。座標は最大6桁の小数点を含む可能性があるため、number(9,6)として定義します。
さらに、監査用のカラムを追加します:created_on、created_by、updated_on、updated_byです。これらはデータが挿入または更新された日時と操作したユーザーを記録します。また、row_versionカラムを追加して楽観的同時実行制御をサポートします。これにより、複数のユーザーが変更を上書きしないようにできます。
ガイドラインに従い、監査用カラムやrow_versionを自動的に更新するトリガーを作成します。このトリガーは挿入または更新の前に実行され、適切なタイムスタンプとユーザー情報を設定します。
テーブル作成後、インデックスも作成する必要があります。主キーはすでにインデックス化されているため、再度インデックスを作成する必要はありません。ただし、外部キーや頻繁に検索されるカラムがある場合、それらに対するインデックスを作成します。
次に、ユーザーの2回目のメッセージを見ると、ISO_CODEを主キーにしてIDカラムを削除したいとのことです。ISOコードは一意性があり、自然キーとして利用できるため、この変更は合理的です。そのため、テーブルを調整し、IDカラムを削除してISO_CODEを主キーとして設定します。
さらに、3回目のやり取りでは、監査用カラムとrow_versionを削除したいとのリクエストがあります。この場合、これらのカラムを削除し、トリガーもそれらを処理しないように更新する必要があります。
このプロセス全体を通じて、Oracleのベストプラクティスを守る必要があります。適切なデータ型や命名規則、制約を使用し、テーブル作成後にトリガーを設定するなど、正しい順序で作業を進めます。
最後に、各変更後にはSQLを検証し、エラーがないか確認します。また、パフォーマンスやデータの整合性を最適化することにも注意を払います。
完
追記1
LM Studioのチャットに指示を入力すると、長考してもタイムアウトは発生しません。ただし、Oracle APEXが挿入しているプロンプトが無いため、生成されるDDLの形式が今ひとつです。
表名や列名のルール、型の選択ルールなどを指示に含める必要があるでしょう。
Oracle APEXから指示しているときは、プロンプトは英語と日本語の混合だったためか、推論の過程は英語で出力されていました。LM Studioのチャットより日本語だけの指示を与えると、推論の過程が中国語で出力されました。
追記2
開発ツールのデバッグは以下の手順で実施します。
管理ツールのアクティビティのモニターを開きます。
アクティブ・セッションを開きます。
デバッグ対象のセッションを見つけて開きます。
デバッグ・レベルを
情報に変更します。
変更の適用をクリックします。
デバッグ・レベルの
トレースはアプリケーションがとても遅くなるため、本当に必要な場合に限り設定します。
エラーが発生した処理を再実行します。
先ほどデバッグ・レベルを情報に設定した画面を開きます。
エラーが補足できていれば、デバッグ・レベルを無効に戻します。変更の適用をクリックします。
該当するエラーのデバッグIDを開きます。
デバッグ・メッセージからエラーの原因を探します。
デバッグ・メッセージより、上記のエラーの原因はORA-29276: 転送がタイムアウトしましたであることがわかります。
この手順は開発ツールのデバッグに限らず、一般ユーザーのセッションを対象にして実施することもできます。
追記終了