こちらの記事の継続になります。
元データとなるCSVファイルのダウンロード
以下のURLより、CSVファイルをダウンロードします。
https://apex.oracle.com/pls/apex/japancommunity/r/simcontents/download?id=Project_and_Tasks_ja.csv
Project, Task Name, Start Date, End Date, Status, Assigned To, Cost, Budgetの列が含まれています。以下はデータの一部ですが、全部で73行含まれます。

データ・ローディング・ウィザードの追加
ページ作成ウィザードを実行し、データ・ローディング・ウィザードのページ群をアプリケーションに追加します。
ページの作成を実行します。

データのロードをクリックします。

データ・ロード定義を新規作成します。定義名は任意ですが、ここではタスクとしています。所有者はそれぞれの環境で異なります。表名はPAC_TASKS(表)を選択します。一意列の列1として、TASK_ID(Number)を選択し、次に進みます。

トランスフォーメーション・ルールを追加します。CSVファイル中のStatus列はOpen、Closed、Pending、On-Holdと大文字と小文字で構成されていますが、表PAC_TASKSのSTATUS列はOPEN、CLOSED、PENDING、ON-HOLDで、大文字のみが登録可能です。ですので、取り込む際に大文字に変換するトランスフォーメーション・ルールを登録します。
トランスフォーメーション・ルールを作成するための列の選択としてSTATUSを選びます。ルール名は任意ですが、ここではSTATUSを大文字にすると設定しています。タイプとして大文字にするを選択し、トランスフォーメーションの追加をクリックします。

ルールの追加を確認し、次へ進みます。

CSVファイルに含まれるProject列はプロジェクト名ですが、表PAC_TASKSのPROJECT_IDは表PAC_PROJECTSのPROJECT_IDを参照する数値です。そのため、表ルックアップを設定することにより、PROJECT_NAMEをPROJECT_IDヘ変換します。
列の新規表ルックアップの追加として、PROJECT_ID(Number)を選択します。ルックアップ定義の設定項目が表示されるので、表名のルックアップとして、PAC_PROJECTS(表)、戻り列として、PROJECT_ID(Number)、アップロード列として、PROJECT_NAME(Varchar2)を指定し、ルックアップの追加をクリックします。

PROJECT_IDのルックアップが登録されているのを確認し、次にASSIGNED_TOについても同様に、人名から表PAC_EMPLOYEESのEMPLOYEE_IDを参照するようにルックアップを追加します。
列の新規表ルックアップの追加として、ASSIGNED_TO(Number)を選択します。ルックアップ定義の設定項目が表示されるので、表名のルックアップとして、PAC_EMPLOYEES(表)、戻り列として、EMPLOYEE_ID(Number)、アップロード列として、EMPLOYEE_NAME(Varchar2)を指定し、ルックアップの追加をクリックします。

追加されたASSIGNED_TOのルックアップを確認し、次に進みます。

ページ・モードをモーダル・ダイアログに変更し、次へ進みます。

ナビゲーションのプリファレンスは新規ナビゲーション・メニュー・エントリの作成を選びます。新規ナビゲーション・メニュー・エントリはデフォルトのデータのロードのまま、変更はしません。次に進みます。

「取消」ボタンでブランチするページ、ページへの「終了」ボタン・ブランチ、双方ともに、とりあえずホームであるページ1に設定します。設定項目はこれで全てなので、作成をクリックします。

これで、データ・ローディング・ウィザードを構成する4枚のページが作成されます。
データのロードを実行する前に、データ・ロード定義に必要な変更があります。共有コンポーネントのデータ・ロード定義を開きます。

直前に作成したデータ・ロード定義、タスクを開きます。

表ルックアップを参照します。リストに新しい値を挿入という列がありますが、PROJECT_IDはこの値がいいえになっています。ASSGINED_TOが参照する表PAC_EMPLOYEESにはすでに従業員情報が投入済みですが、表PAC_PROJECTSには、まだデータが投入されていません。表PAC_TASKSへのデータ・ロード時に表PAC_PROJECTSにデータが投入されるよう、この値をはいへ変更します。
列名のPROJECT_IDをクリックし、表ルックアップの定義を開きます。
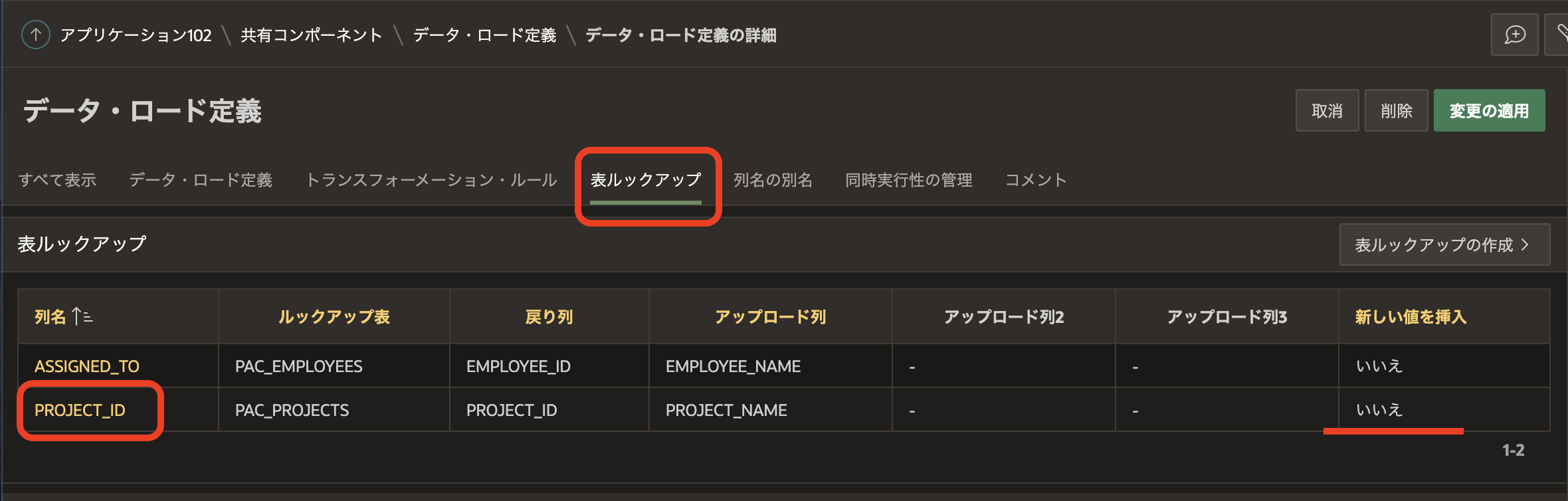
新しい値を挿入をはいに変更し、変更の適用をクリックします。

必要な変更は以上です。
アプリケーションを実行し、データのロードを行います。
まだアクセス制御は実装していないので、ユーザーは誰を選択しても構いません。サインインをした後、サイド・メニューよりデータのロードを呼び出します。
インポート元として、ファイルをアップロード(カンマ区切り(*.csv)またはタブ区切り)を選択し、ファイル名として記事の最初に指示しているリンク先よりダウンロードしたProject_and_Tasks_ja.csvを設定します。1行目に列名があるのチェックを確認し、その下の詳細設定の使用にチェックを入れます。ファイルの文字セットの指定が現れるので、日本語(Shift JIS)を選択します。以上で次に進みます。

データと列のマッピングでソース列がPROJECTのみターゲット列がロードしないになっています。このターゲット列をPROJECT_ID(Number)に変更します。これ以外はCSVの一列目のソース列名と、表PAC_TASKSの列名が一致しているため、ターゲット列が適切に選択されます。ターゲット列がすべて適切に指定されていることを確認し、次へ進みます。

データ検証の結果を確認し、データのロードをクリックします。

挿入された行が73行であれば全行ロードが成功しています。終了をクリックします。

これでCSVファイルのアップロードが完了し、表PAC_TASKS、PAC_PROJECTSへデータがロードされました。データが準備できたので、次からはデータの操作を行う画面を実装していきます。
最初に実装するのは、ファセット検索です。