Oracle REST Data Servicesで表のAutoRESTを有効にすると、Batch LoadというCSVファイルをアップロードする機能が使えます。
Oracle REST Data Services Developer's Guide Release 25.1
公式のドキュメント以外では、以下のブログ記事でBatch Loadが紹介されています。
Move Large Volumes of Data Over REST with APEX & ORDS
Bulk Load an Oracle Table from CSV via RESTBatch Loading CSV to Oracle Database, Again, via REST APIsBatch Loadは手元のCSVファイルの内容を、AutoRESTを有効にしたデータベースの表にアップロードする機能です。SQLclのLOADコマンドやその他の方法と比較して特別に速いというわけではありませんが、curlコマンドが実行できればデータのロードができるという手軽さがあります。
以下より、Batch Loadを実際に試してみます。
APEXの対話モード・レポートからダウンロードしたCSVファイルを、AutoRESTを有効にした表にアップロードしてみます。
対話モード・レポートのページを持つAPEXアプリケーションを作成します。
アプリケーション・ビルダーよりアプリケーションの作成を開始します。
名前はCar Accidentsとして、ファイルからのアプリケーションの作成をクリックします。
コピー・アンド・ペーストを選択し、サンプルのCSVデータとして車両速度を選択します。Posted Speed, Vehical Speed, Date of Incedent, License Plate, Location, Stateといったデータが貼り付けられます。Vehical、Incedentはスペルが間違っていますが、列名は後で日本語にするので、そのまま作業します。
次へ進みます。
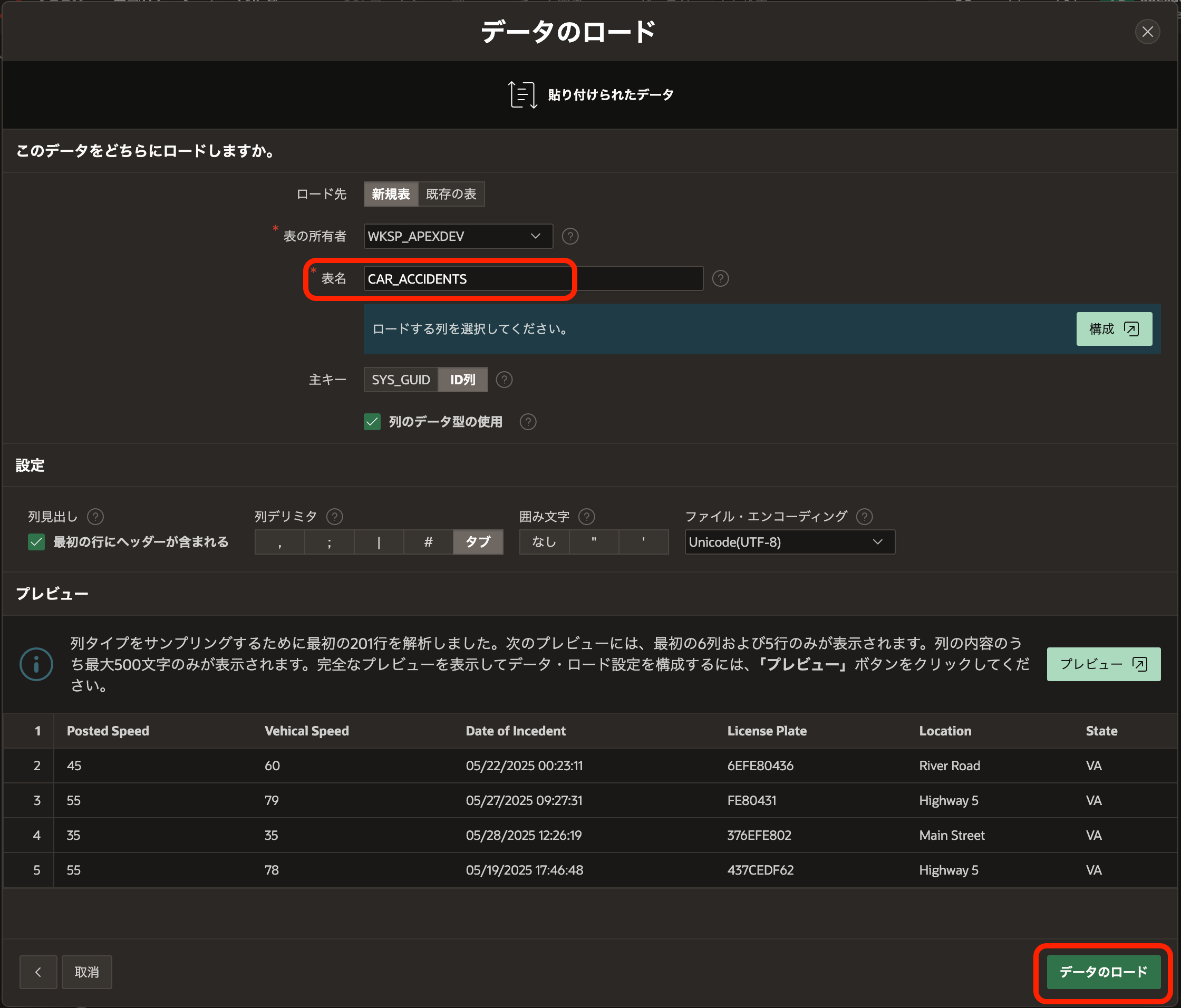
データをロードする表名はCAR_ACCIDENTSとします。
データのロードをクリックします。
610行のデータが表CAR_ACCIDENTSに保存されます。
アプリケーションの作成をクリックします。
アプリケーション作成ウィザードが起動します。
今回はCar Accidentsレポートの対話モード・レポートのページだけを使用します。その他のページは削除します。
ページをCar Accidentsレポートだけにして、アプリケーションの作成をクリックします。
アプリケーションCar Accidentsが作成されます。
ダウンロードされるCSVファイルの文字エンコーディングを設定します。
アプリケーション定義を開きます。
グローバリゼーションを開きます。
アプリケーションのプライマリ言語が日本語(ja)の場合、自動CSVエンコーディングをオンにするとダウンロードするCSVファイルの文字エンコーディングはShift-JISになります。オフの場合はUTF-8です。
今回はORDSにアップロードします。CSVファイルの文字エンコーディングはUTF-8が都合が良いため、自動CSVエンコーディングをオフにして変更を適用します。
CSVファイルをダウンロードするのに使用する対話モード・レポートのページを編集します。
ダウンロードするCSVファイルの名前を設定します。
リージョンCar Accidentsの属性タブを開き、ダウンロードのファイル名に以下を設定します。
car_accidents-&SYSDATE_YYYYMMDD.
この設定により、対話モード・レポートからダウンロードしたCSVファイルのファイル名はcar_accidents-20250613.csvのようになります。
ファイル名が設定されていないと、リージョンの識別の名前がファイル名として使用されます。今回の例ではCar Accidents.csvとなります。ファイル名に空白が含まれることになり、扱いにくくなります。
対話モード・レポートの列のヘッダーが、ダウンロードされるCSVファイルの列名になります。
列POSTED_SPEEDのヘッダーは制限速度とします。
同様に列VEHICAL_SPEEDは車両速度、列DATE_OF_INCEDENTは事故発生日、列LICENSE_PLATEはナンバープレート、列LOCATIONは場所、列STATEは州とします。
以上を設定してアプリケーションを実行します。
対話モード・レポートのヘッダーは、以下のように日本語で表示されます。
ページ・デザイナに戻り、列IDのタイプをプレーン・テキストに変更します。
タイプが非表示の場合、ダウンロードするCSVファイルに列として含めることができなくなります。
対話モード・レポートの作成後に表示可能にした列は、最初はレポート上で非表示になります。
ダウンロードの対象にするには、列を表示する必要があります。
アクションの列を開きます。
表示しないにあるIDをレポートに表示に移動し、適用をクリックします。
レポート上にID、制限速度、車両速度、事故発生日、ナンバープレート、場所、州が表示されます。
対話モード・レポートに一覧されているデータを、CSVファイルにダウンロードします。
アクションのダウンロードを開きます。
レポート形式として
CSVを選択し、
ダウンロードをクリックします。
結果として以下の内容を含むファイルが、
car_accidents-20250613.csvのような日付付きのファイル名でダウンロードされます。
ID,制限速度,車両速度,事故発生日,ナンバープレート,場所,州
473,25,23,2025/05/30,6EFE807,School Road,VA
483,25,27,2025/05/14,E80455B2,School Road,VA
488,25,21,2025/05/31,EFE80456,School Road,VA
494,25,43,2025/05/18,E804564,School Road,VA
497,25,20,2025/05/13,EFE80455,School Road,VA
506,25,33,2025/05/16,E063A15D6,School Road,VA
522,25,22,2025/05/13,2EDF6E2,School Road,DC
[略]
このCSVファイルのアップロード先となる表を作成します。
表の名前はCAR_ACCIDENTS_JAとします。以下のDDLを実行します。
主キー列のIDはデータのインサート時に値を設定できるようにby default on nullを付けます。列名はCSVのヘッダーに一致するように日本語にします。
create table car_accidents_ja
(
"ID" number generated by default on null as identity not null,
"制限速度" number,
"車両速度" number,
"事故発生日" date,
"ナンバープレート" varchar2(50),
"場所" varchar2(50),
"州" varchar2(50),
primary key ("ID") using index enable
);
作成した表CAR_ACCIDENTS_JAのAutoRESTを有効にします。
begin
ords.enable_object(
p_enabled => true
,p_schema => '表CAR_ACCIDENTS_JAがあるスキーマ'
,p_object => 'CAR_ACCIDENTS_JA'
,p_object_type => 'TABLE'
,p_object_alias => 'car_accidents_ja'
,p_auto_rest_auth => false
);
end;
今回は検証ということで、p_auto_rest_authはfalseとしています。実際はtrueを設定し、必ずAutoRESTの呼び出しを保護します。
表CAR_ACCIDENTS_JAのAutoRESTに関する設定を確認します。
select * from user_ords_objects where parsing_object = 'CAR_ACCIDENTS_JA'
ダウロードしたCSVファイルを、Batch Loadを呼び出して表CAR_ACCIDENTS_JAにアップロードします。
Batch Loadのエンドポイントは以下の形式になります。
https://[ホスト名]/ords/[ワークスペース名]/[オブジェクト別名]/batchload
このエンドポイントはSQL Developer Webを開いて確認することができます。
SQLワークシートのナビゲータより対象の表でコンテキスト・メニューを開き、RESTからcURLコマンド...を実行します。
AutoRESTとして呼び出せる操作と、それに対応したcURLコマンドの例が表示されます。
以下のcurlコマンドを実行します。オプションとしてbatchRows=100およびdateFormat=YYYY/MM/DDを与えています。
Batch Loadのオプションについては、ドキュメントを参照してください。
% curl -H"Content-Type: text/csv" --data-binary @car_accidents-20250613.csv 'https://*********-apexdev.adb.us-ashburn-1.oraclecloudapps.com/ords/apexdev/car_accidents_ja/batchload?batchRows=100&dateFormat=YYYY/MM/DD'
#INFO Number of rows processed: 610
#INFO Number of rows in error: 0
#INFO Last row processed in final committed batch: 610
SUCCESS: Processed without errors
%
表CAR_ACCIDENTSに保存されている行数が610なので、#INFO Number of rows processed: 610と返されれば、すべての行がアップロードできています。
確認のためアップロードしたデータをダウンロードします。AutoRESTのGET ALLを呼び出し、JSON形式でファイルに保存します。ページングをせずに全行を取得するためlimit=1000を指定します。
curl -o car_accidents.json 'https://[ホスト名]/ords/[ワークスペース名]/car_accidents_ja/limit=1000'
% curl -o car_accidents.json 'https://**********-apexdev.adb.us-ashburn-1.oraclecloudapps.com/ords/apexdev/car_accidents_ja/?limit=1000'
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 176k 0 176k 0 0 142k 0 --:--:-- 0:00:01 --:--:-- 142k
%
ダウンロードしたJSONをjqコマンドでCSV形式に変換します。
jq -r ' .items[] | [ .id, ."制限速度", ."車両速度", ."事故発生日", ."ナンバープレート", ."場所", ."州" ] | @csv ' car_accidents.json > result.csv% jq -r ' .items[] | [ .id, ."制限速度", ."車両速度", ."事故発生日", ."ナンバープレート", ."場所", ."州" ] | @csv ' car_accidents.json > result.csv
%
生成したCSVファイルresult.csvの内容を確認します。行数は610になります。
wc -l result.csv
head -10 result.csv
% wc -l result.csv
610 result.csv
% head -10 result.csv
160,55,48,"2025-05-30T00:00:00Z","EDF6E06","Highway 5","VA"
162,55,52,"2025-05-28T00:00:00Z","FE80443","Highway 5","VA"
166,55,55,"2025-05-13T00:00:00Z","EDF6E0631","Highway 5","VA"
169,55,63,"2025-06-06T00:00:00Z","76EFE8045","Highway 5","VA"
170,55,53,"2025-05-18T00:00:00Z","4422ED8","Highway 5","VA"
171,55,51,"2025-06-03T00:00:00Z","063A15D7","Highway 5","VA"
172,55,50,"2025-06-07T00:00:00Z","24EDF6E8","Highway 5","VA"
174,55,59,"2025-05-30T00:00:00Z","E804424","Highway 5","VA"
175,55,48,"2025-06-08T00:00:00Z","6EFE80446","Highway 5","VA"
177,55,57,"2025-06-09T00:00:00Z","E063A158","Highway 5","PA"
%
AutoRESTを保護した場合、つまりORDS.ENABLE_OBJECTの実行時にp_auto_rest_authにtrueを指定した場合は、p_schemaに指定したスキーマをユーザー名、そのスキーマのパスワードをパスワードとして、REST呼び出しを認証します。
begin
ords.enable_object(
p_enabled => true
,p_schema => '表CAR_ACCIDENTS_JAがあるスキーマ'
,p_object => 'CAR_ACCIDENTS_JA'
,p_object_type => 'TABLE'
,p_object_alias => 'car_accidents_ja'
,p_auto_rest_auth => true
);
end;
curlコマンドでは-uまたは--userオプションでユーザー名、パスワードを指定します。結果としてREST APIとして発行されるHTTPリクエストにBasic認証が設定されます。
curl -u スキーマ名:パスワード ....
OAuth2のクライアントクリデンシャル認証でも保護できますが、その場合はcurlコマンドで簡単にBatch Loadを呼び出すということは難しくなります。そのため、実際にはBatch LoadでCSVファイルをアップロードする表は、それ用のスキーマを作成して最小権限で運用することになりそうです。
今回の記事は以上になります。
完