プロシージャ
DBMS_CLOUD.CREATE_CREDENTIALを呼び出します。
認証トークンの生成手順は、本記事の末尾の
準備作業のセクションに記載しています。
SQL> set echo on
SQL> @credential
SQL> begin
2 dbms_cloud.create_credential
3 (
4 credential_name => 'DEF_CRED'
5 , username => 'ユーザー名'
6 , password => '認証トークン'
7 );
8 end;
9 /
PL/SQLプロシージャが正常に完了しました。
SQL>
プロシージャDBMS_CLOUD.EXPORT_DATAを呼び出し、表BRICKSの内容をオブジェクト・ストレージにエクスポートします。エクスポート先のバケットはbricks、作成されるファイルの接頭辞はbricksとします。
SQL> set echo on
SQL> set time on timing on
16:03:28 SQL> @export_data
16:03:32 SQL> declare
2 C_REGION constant varchar2(20) := 'us-ashburn-1';
3 C_NAMESPACE constant varchar2(20) := 'ネームスペース名';
4 C_BUCKET constant varchar2(20) := 'bricks';
5 C_FILENAME constant varchar2(20) := 'bricks';
6 l_path varchar2(400);
7 begin
8 l_path := 'https://objectstorage.' || C_REGION || '.oraclecloud.com/n/' || C_NAMESPACE
9 || '/b/' || C_BUCKET || '/o/' || C_FILENAME;
10 dbms_output.put_line(l_path);
11 dbms_cloud.export_data
12 (
13 credential_name => 'DEF_CRED'
14 , file_uri_list => l_path
15 , format => json_object('type' value 'csv')
16 , query => 'SELECT * FROM bricks'
17 );
18 END;
19 /
PL/SQLプロシージャが正常に完了しました。
経過時間: 00:00:40.333
経過時間: 00:00:40.333
16:04:12 SQL>
バケットbricksの内容を確認します。バケット内に複数のオブジェクトが作成されていることが確認できます。
エクスポートしたオブジェクトを参照する外部表
BRICKS_EXTを作成します。
SQL> set echo on
SQL> set time on timing on
16:19:04 SQL> @create_external_table
16:19:09 SQL> declare
2 C_REGION constant varchar2(20) := 'us-ashburn-1';
3 C_NAMESPACE constant varchar2(20) := 'ネームスペース名';
4 C_BUCKET constant varchar2(20) := 'bricks';
5 C_FILENAME constant varchar2(20) := 'bricks';
6 l_path varchar2(400);
7 begin
8 l_path := 'https://objectstorage.' || C_REGION || '.oraclecloud.com/n/' || C_NAMESPACE
9 || '/b/' || C_BUCKET || '/o/' || C_FILENAME || '*.csv';
10 dbms_output.put_line(l_path);
11 dbms_cloud.create_external_table(
12 credential_name => 'DEF_CRED'
13 , table_name => 'bricks_ext'
14 , file_uri_list => l_path
15 , format => json_object(
16 'type' value 'csv',
17 'dateformat' value 'RR-MM-DD')
18 , column_list =>
19 'brick_id number,
20 colour varchar2(6),
21 shape varchar2(8),
22 weight number,
23 insert_date date,
24 junk varchar2(50)'
25 );
26 end;
27 /
PL/SQLプロシージャが正常に完了しました。
経過時間: 00:00:00.423
経過時間: 00:00:00.424
16:19:10 SQL>
表BRICKS_EXTが作成されたので、行数を確認します。
16:48:04 SQL> select count(*) from bricks_ext;
COUNT(*)
___________
4789278
経過時間: 00:00:19.441
16:49:51 SQL>
元の表BRICKSは10,000,000行なので、半分程度しかエクスポートされていません。
足りない行を確認してみます。
16:49:51 SQL> select * from (
2 select * from bricks
3 minus
4 select * from bricks_ext
5* ) where rownum < 10;
BRICK_ID COLOUR SHAPE WEIGHT INSERT_DATE JUNK
___________ _________ ___________ _________ ______________ _____________________________________________________
260102 blue pyramid 9 11-04-19 xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
260103 blue prism 9 11-04-19 xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
260104 blue cube 3 11-04-19 xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
260105 blue cylinder 10 11-04-19 xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
260106 blue pyramid 7 11-04-19 xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
260107 blue prism 2 11-04-19 xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
260108 blue cube 7 11-04-19 xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
260109 blue cylinder 10 11-04-19 xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
260110 blue pyramid 7 11-04-19 xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
9行が選択されました。
経過時間: 00:00:26.803
16:52:26 SQL>
少なくとも、BRICK_IDが260102から始まる行がエクスポートされていません。エクスポートされたオブジェクトをダウンロードして確認しました。
データが出力されるオブジェクト名が秒単位であるため、出力が速いと上書きしているように見えます。
上書きをさせない指定などがあるのかもしれませんが、調べても見つけることはできませんでした。残念ながら、今回の用途でDBMS_CLOUD.EXPORT_DATAは使用できません。
追記 - DBMS_CLOUD.EXPORT_DATAだけで処理できました。手順の最終版としては
こちらになります。速度も比較にならないほど速いです。
これ以降の内容は表データのエクスポートでは使うことはないと思います。APEXのAPIをAPEX以外から使用する方法の、ひとつの例として残しておきます。
CSVの生成とアップロードを別々に実施
Oracle APEXが提供しているPL/SQL APIのファンクション
APEX_DATA_EXPORT.EXPORTを呼び出しCSV形式のエクスポートを行い、オブジェクト・ストレージを操作するPL/SQL SDKを使ってオブジェクト・ストレージへアップロードします。
アプリケーション作成ウィザードを実行します。名前は外部表の操作とし、それ以外は設定せず、アプリケーションの作成を実行します。
アプリケーションが作成されたら、ページ・デザイナでホーム・ページを開きます。
タイプが静的コンテンツのリージョンをひとつ作成し、そこにページ・アイテムとしてP1_START_ROWおよびP1_END_ROWを作成します。双方ともタイプは数値フィールドとします。
オブジェクト・ストレージを操作するPL/SQL SDKを呼び出す権限を、APEXのワークスペース・スキーマに与えます。
管理ユーザーADMINにて実行します。
grant execute on dbms_cloud to apexdev;
grant execute on dbms_cloud_oci_obs_object_storage to apexdev;
grant execute on DBMS_CLOUD_OCI_OBS_OBJECT_STORAGE_PUT_OBJECT_RESPONSE_T to apexdev;
PL/SQL SDKの呼び出しに指定するクリデンシャルMY_OCI_CREDを作成します。作成済みのAPIキーを使用します。APIキーの作成手順は、本記事の末尾にある準備作業に記載しています。
SQL> @create_api_cred
SQL> begin
2 dbms_cloud.create_credential(
3 credential_name => 'MY_OCI_CRED'
4 , user_ocid => '構成ファイルのuserの値'
5 , tenancy_ocid => '構成ファイルのtenancyの値'
6 , private_key => '一行にした秘密キー'
7 , fingerprint => '構成ファイルのfingerprintの値'
8 );
9 end;
10 /
PL/SQLプロシージャが正常に完了しました。
SQL>
10万行ごとにファイルを分割し、表BRICKSの内容をオブジェクト・ストレージにアップロードします。以下のスクリプトを実行します。
オブジェクト・ストレージへ保存するデータは圧縮しています。非圧縮で保存する方法もコードに含めています。また、OCI PL/SQL SDKではなく、DBMS_CLOUD.PUT_OBJECTを呼び出す方法についてもコードに含めています。
北米リージョン(us-ashburn-1)で実行したところ、すべてのデータがアップロードされるまでに40分程度の時間がかかりました。
外部表の作成には以下のスクリプトを作成します。外部表BRICKS_EXTが作成済みの場合は、あらかじめ削除しておきます。
drop table bricks_ext;
APEX_DATA_EXPORT.EXPORTを呼び出してCSV形式での出力を行なっているため、出力されたすべてのファイルにヘッダーが含まれています。そのためformatにskipheadersを含めています。
作成された外部表BRICKS_EXTの内容が、元の表であるBRICKSと同じかどうか確認します。
12:16:52 SQL> select count(*) from bricks_ext;
COUNT(*)
___________
10000000
経過時間: 00:00:17.975
12:17:17 SQL> select * from bricks
2 minus
3* select * from bricks_ext;
行が選択されていません
経過時間: 00:00:39.345
12:18:09 SQL>
行数も10,000,000であり元表との差分もないため、表の内容は同一と言えます。
パーティションに分割
Autonomous Databaseでは、パーティション機能を使用するに当たって追加の費用は発生しません。そのため、100,000行ごとにファイルを分割するよりは、最初からパーティション表として作成するつもりで、データをエクスポートする方が合理的です。
表BRICKSを列INSERT_DATAの年ごとにパーティション分割できるように、オブジェクト・ストレージへデータをアップロードします。データのアップロード後にパーティション分割された外部表を作成します。
最初にAPEXアプリケーションにページ・アイテムP1_YEARを作成します。
表BRICKSを年単位で分けて、オブジェクト・ストレージにアップロードします。
行数で分割するよりコードはわかりやすくなっています。
アップロードされたオブジェクトは以下のようになります。
外部表を作成します。プロシージャDBMS_CLOUD.CREATE_EXTERNAL_PART_TABLEを呼び出します。
表BRICKS_PART_EXTが作成されます。
元の表であるBRICKSとデータが同じであるか確認します。
15:10:30 SQL> select count(*) from bricks_part_ext;
COUNT(*)
___________
10000000
経過時間: 00:00:30.637
15:15:31 SQL> select brick_id,colour,shape,weight,insert_date,
2 to_char(insert_date,'RRRR') year, junk from bricks
3 minus
4* select * from bricks_part_ext;
行が選択されていません
経過時間: 00:00:47.329
15:17:03 SQL>
行数が10,000,000行あり、表BRICKSとの差分もないので、データは同じであることが確認できました。
元々は外部表のINMEMORYオプションを試すつもりだったのですが、それができるのは21cからでした。自分が目的としていた作業はできませんでしたが、これまで記載した手順が何かの参考になれば幸いです。
準備作業
管理ユーザーADMINにてデータベース・アクションに接続し、データベース・ユーザーを開き、ユーザーAPEXDEVのRESTの有効化を実施します。
Autonomous Databaseのコンソールより
DB接続を実行し、DB接続に使用するウォレット・ファイルをダウンロードします。今回の例ではデータベース名は
DWAPEXなので、
Wallet_DWAPEX.zipになります。
グループAdministratorsに所属しているユーザーにて、認証トークンを生成します。
APIアクセスに使用するクリデンシャルとなるユーザーに管理者を使うのことは、セキュリティ上望ましくありません。別にユーザーを作成し、必要最小限の権限を与えた上で認証トークン(このあとにAPIキーも同様)を生成することを推奨します。
生成した認証トークンはどこかに保存しておきます。データベース側で、オブジェクト・ストレージにアクセスする際のクリデンシャルとして使用します。
オブジェクト・ストレージに、バケットbricksを作成しておきます。
データを保存するオブジェクト・ストレージのリージョンとネームスペースを確認しておきます。
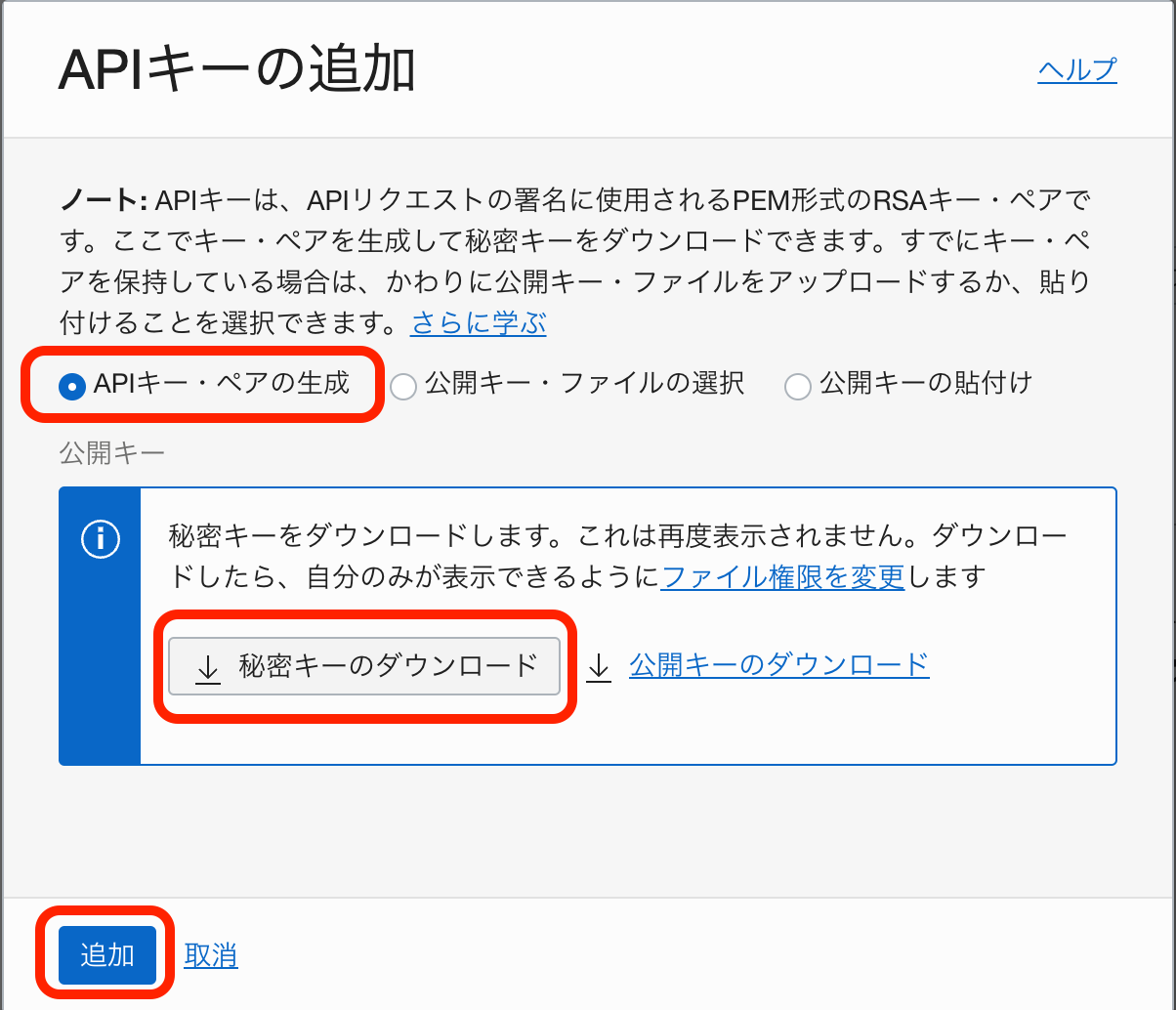
PL/SQL SDKを呼び出すときに使用する、APIキーを作成します。
APIキーの追加をクリックします。
APIキー・ペアの作成を選択し、秘密キーのダウンロードをクリックします。
追加をクリックします。
構成ファイルのプレビューが表示されます。この内容をコピーし、どこかに保存しておきます。PL/SQL SDKを呼び出すときに使用するクリデンシャルを作成する際に使用します。
APIキーを追加したときにダウンロードされた秘密キーのファイルの内容は、ヘッダーを削除した上で一行にする必要があります。
以下のシェル・スクリプトにダウンロードされたファイル名を引数として与えることにより、DBMS_CLOUD.CREATE_CREDENTIALのprivate.keyとなるデータを作成できます。
#!/bin/sh
while read l
do
test ${l:0:1} != "-" && echo $l | tr -d '\r\n'
done < $1
echo
本編に含まれなかった準備作業の説明は以上になります。
参考にしたサイト
Export BLOB Contents Using UTL_FILE
パーティション化された外部表の作成について、オラクルの公式ブログの記事を参照しています。