Oracle APEXではアップロードしたファイルを表に読み込むツールとして、データ・ワークショップを提供しています。以下のファイル形式をサポートしてます。
- CSV (拡張子.txtもCSV形式のファイルとして選択可能)
- XLSX
- XML
- JSON

今回は東京都から、東京都_新型コロナウイルス陽性患者発表詳細として提供しているCSV形式のオープンデータを、前の記事で作成した表COVID19_PATIENTSに取り込んでみます。
東京都のデータの取得
東京都が開設した新型コロナウイルス感染症対策サイトを開きます。
新規患者に関する報告件数の推移からオープンデータを入手します。該当リンクをクリックします。

探索からダウンロードします。

または、東京都_新型コロナウイルス陽性患者発表詳細のリンクをクリックし、その後リソースへ行くをクリックしてファイルをダウンロードします。

ダウンロードしたCSV形式のファイル名称は130001_tokyo_covid19_patients.csvです。このファイルをデータベースに取り込みます。
データ・ワークショップによるデータ・ロード
SQLワークショップからユーティリティを開き、データ・ワークショップを実行します。

データ・ワークショップはデータのロード以外にアンロードにも対応しています。今回はデータのロードを実行します。

デフォルトでファイルのアップロードが選択されています。ファイルの選択をクリックし、先ほどダウンロードしたCSVファイルを選択します。ファイルのアップロード以外にコピー・アンド・ペーストによるデータの投入も可能です。

ファイルを選択すると、即座にデータのアップロードが開始します。アップロードが完了すると、アップロードしたデータのプレビューが表示されます。

今回は既存の表へデータを取り込みます。そのため、以下の新規表への取り込みの説明について、操作は不要です。
ちなみに新規表に特有の指定項目としては、以下があります。
表名
新規に作成される表の名前です。
主キー
主キー列は列名をIDとして、新たに追加されます。ID列を選択すると、以下の列が加わります。(データベースのバージョンに依存します)"ID" NUMBER GENERATED ALWAYS AS IDENTITY MINVALUE 1 MAXVALUE 9999999999999999999999999999 INCREMENT BY 1 START WITH 1 CACHE 20 NOORDER NOCYCLE NOKEEP NOSCALE NOT NULL ENABLE"ID" NUMBER DEFAULT to_number(sys_guid(),'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX')列のデータ型の使用
表名を指定すると構成ボタンが現れます。

構成をクリックすると、サンプリングする行数の指定とロードする列の指定ができます。

新規に作成される表の列のデータ型はサンプリングした行から導出されます。例えば200行のサンプリングを行い、その中での最長のデータが30バイトであれば、それを考慮してデータ型が決定されます。余裕をみて50バイト程度になります。しかし、データ全体をロードしたときに長さが100バイトのデータがあると、その行はエラーとなりデータとしては取り込まれません。
そのようなエラーを回避するためには、サンプリングする行を十分大きくするか、この列データの使用のチェックを外します。このチェックを外すと列のデータ型はすべてVARCHAR2(4000)になります。データ型を厳密に決めたい場合は、表をあらかじめ作成した上で、既存の表にデータをロードした方が合理的です。一時的にデータをアップロードするインターフェース表のような扱いの場合は、列データの使用のチェックを外すのも有効です。
今回は既存の表にデータをロードするので、ロード先として既存の表を選択し、表としてCOVID19_PATIENTSを指定します。最初のロードなので、Updateメソッドは追加でも置換でも同じ結果になります。Updateメソッドの影響については後述します。そして構成をクリックして、列のマッピングを定義します。

列のマッピングには以下を定義します。
列のマッピングの指定画面です。すでに列のデータ型は決定しているためサンプリングする行を変更する必要はあまりありません。マップ先の指定ができたら、変更の保存をクリックします。

東京都が提供しているデータは、陽性患者属性として定義されているデータの全てではありません。実際のところ、それぞれ都道府県毎で、提供しているデータは異なっています。
元々、新型コロナウイルス感染症対策に関するオープンデータ項目定義書は、東京都での開発実績を元にして作成されています。そのため、提供されているデータは変更せずにマップした列へ取り込むことができます。
データとして取り込む列の指定ができたので、データのロードを実行します。

データのロード中の経過が表示され、ロードが完了すると以下の画面になります。ファイルに含まれる全行がロードできていることを確認します。エラーのため取り込みができなかった行は表COVID19_PATIENTS_ERR$に書き込まれます。

すでにロードしたデータを表示するためのアプリケーションは作成済みなので、取消をクリックして、画面を閉じます。
データ・ワークショップを使用したデータの取り込みは以上で完了です。
取り込んだデータの確認
作成済みのアプリケーション、新型コロナウイルス感染症陽性患者属性を実行し、取り込まれたデータを確認します。陽性患者一覧のレポートを表示します。チャートを表示するため、アクション・メニューからチャートを実行します。
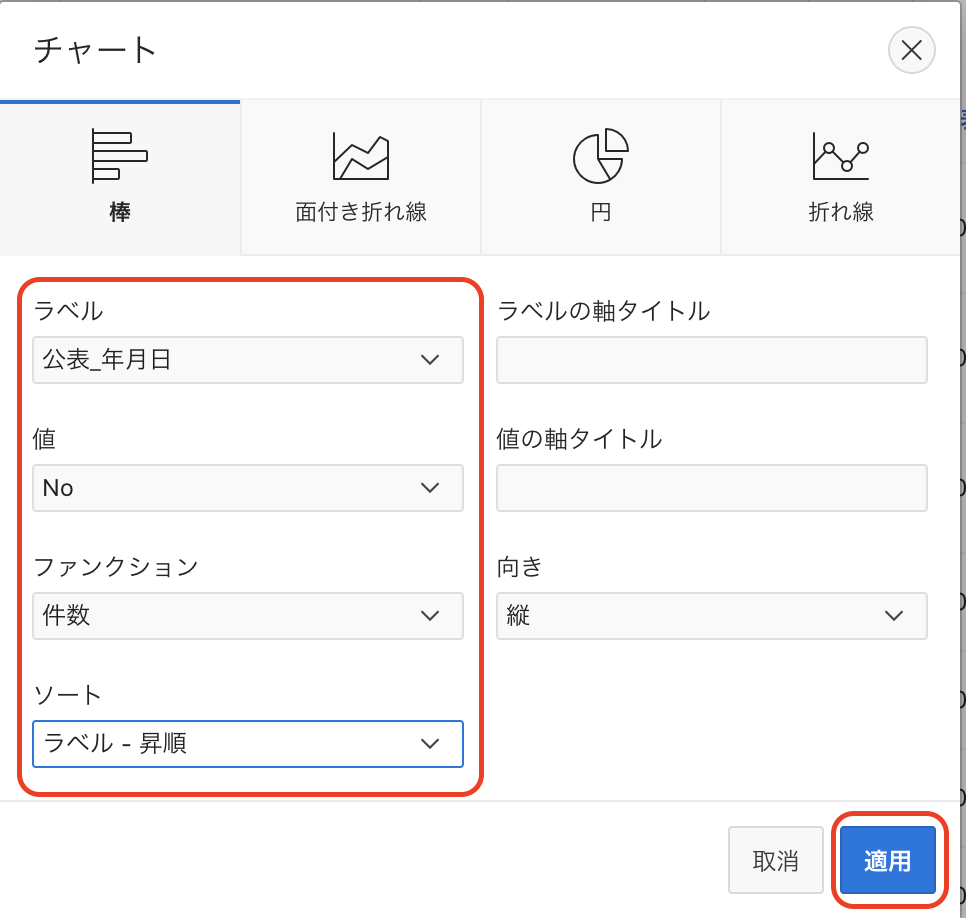
チャートの条件として以下を指定し、適用をクリックします。
チャート: 棒
ラベル: 公表_年月日
値: No
ファンクション: 件数
ソート: ラベル - 昇順
向き: 縦
対話モード・レポートの簡易グラフとして、以下が表示されます。

以上で、取り込まれたデータの確認ができました。
データ・ワークショップの制限
東京都は、東京都_新型コロナウイルス陽性患者発表詳細のデータを毎日更新しています。公開しているURLの変更はしていません。そのため、更新分を取り込むには同じファイルをダウンロードし、表COVID19_PATIENTSの内容を入れ替えます。
この場合、Updateメソッドとして置換を選択することで、すでに表に保存されているすべての行を削除した上で、ファイルの内容に置き換えることができます。追加を選ぶと既存の行はそのまま残るため、(東京都が提供しているデータは差分ではないので)過去のデータが2重に保存されることになります。
今回は表COVID19_PATIENTSに全都道府県の情報を取り込むことを想定しています。なので、福井県のデータを追加で取り込んでみます。福井県が提供している新型コロナウイルス感染症の陽性患者のデータはオープンデータとして提供されていて、こちらからダウンロードできます。

covid19_patients.csvのファイルをダウンロードし、東京都と同様にデータ・ワークショップを使って表COVID19_PATIENTSにロードします。ファイルに含まれている属性が異なり、列のマッピングに違いがありますが、東京都での指定と大きな違いはありません。
Updateメソッドは追加を選びます。置換を選ぶとすでに保存されている東京都のデータが削除されてしまいます。

構成を開いて設定する列のマッピングは以下のように定義します。
設定が完了したら、データのロードを実行します。
ロードされた福井県のデータを確認します。先ほどのチャートの画面で、アクションからフィルタを選択します。

フィルタの条件として、都道府県名を福井県と指定します。

福井県として取り込んだデータがグラフ表示されます。

この後、データを更新するために、東京都の更新を読み込む、または、福井県の更新を読み込もうとすると、どのようになるでしょうか。
東京都だけ、もしくは、福井県だけ、データを更新するということは、データ・ワークショップではできません。Updateメソッドに追加を選ぶとデータが2重になり、置換を選ぶと東京都と福井県の両方とも削除されてしまいます。
例えば以下のSQLをあらかじめ実行すると、Updateメソッドとして追加を選んでデータの更新ができます。
delete from covid19_patients where prefecture_name = '東京都';delete from covid19_patients where prefecture_name = '福井県';