概要(列ABSTRACT)の内容から'#'で始まるタグを抽出し、ファイルの検索に利用します。
タグの抽出にはAPEX_STRING_UTIL.FIND_TAGSを使用します。
せっかくタグを抽出するので、それをマルチバリュー・ファセットとして使うファセット検索のページを作成します。
以下の動作をするページを作成します。

タグの抽出処理の追加
表SFM_CONTENTSに列TAGSを追加します。抽出したタグはJSON配列として保存します。Autonomous DatabaseのDB19cを想定しているため、format osonの指定を加えています。
alter table sfm_contents add (tags blob check (tags is json format oson));
ページ番号3のフォームのページに、新たにプロセスを追加します。
プロセスの識別の名前はタグの抽出とし、タイプはコードの実行を選択します。実行するPL/SQLコードとして以下を記述します。
update sfm_contents set tags =
json_object(apex_string_util.find_tags(:P3_ABSTRACT))
where id = :P3_ID;サーバー側の条件として、タイプにリクエストは値に含まれるを選択し、値としてCREATE SAVEを設定します。
ファイルの削除の下、ダイアログを閉じる - ファイル無しの上に配置します。

ファセット検索の追加
ファセット検索のページを作成します。
ページの作成を実行します。

ファセット検索を選択します。

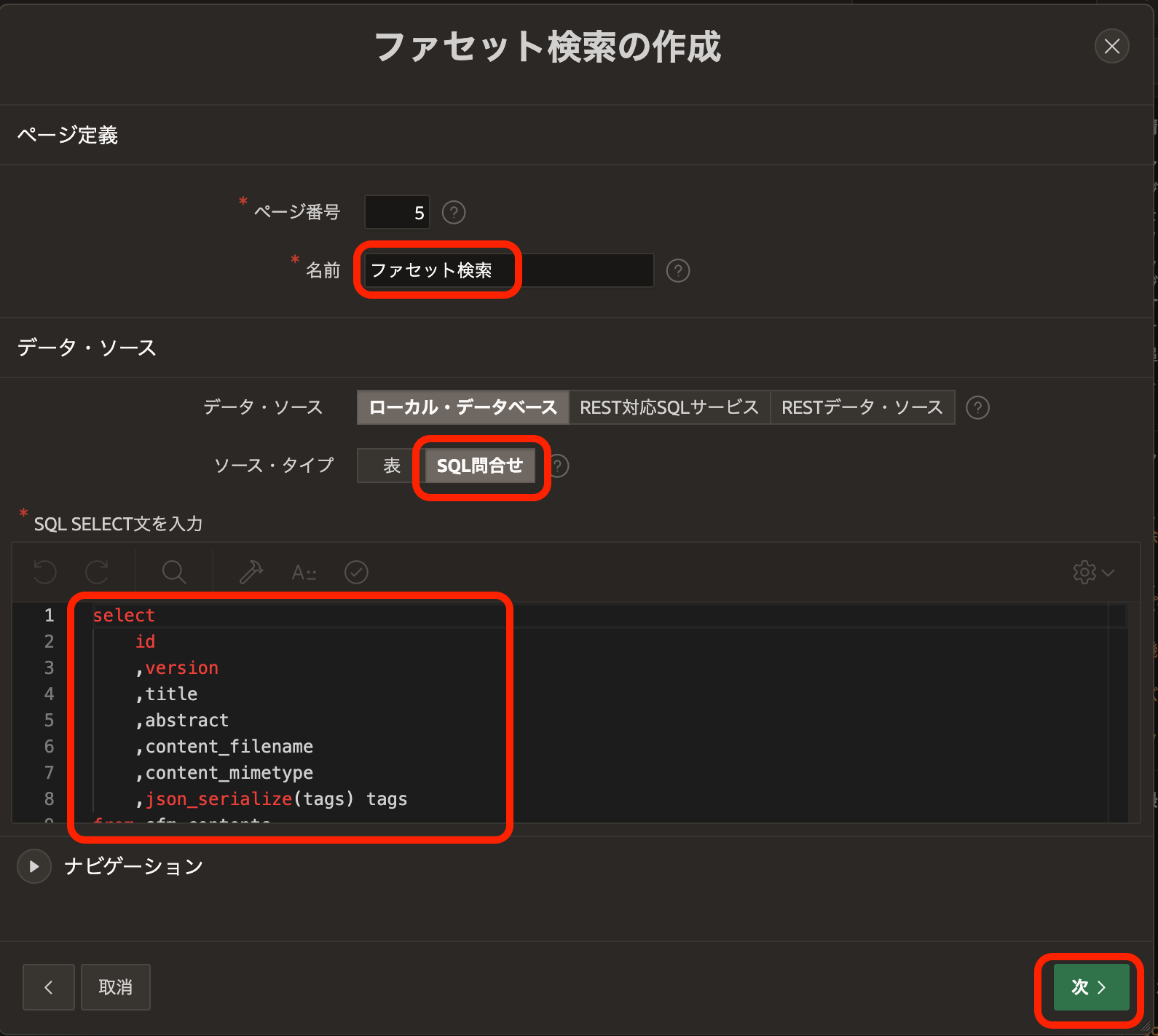
ページ定義の名前はファセット検索とします。データ・ソースのソース・タイプにSQL問合せを選択し、SQL SELECT文を入力に以下を記述します。
ナビゲーションはデフォルトから変更しません。デフォルトの設定で、ブレッドクラムとナビゲーション・メニューが作成されます。
次へ進みます。
表示形式はレポート、ファセットとして使用する列としてCONTENT_MIMETYPEとTAGSを選択します。
ページの作成を実行します。

ファセット検索のページが作成されます。
ファセットP5_TAGSは、JSON配列をデータとしたマルチバリュー・ファセットです。
自動的に認識されていないため、複数の値のタイプをJSON配列に変更します。フィルタの結合はAND(論理積)を選択しています。

レポート検索結果の列IDとVERSIONの識別のタイプを非表示に変更します。

対話モード・レポートと同様に、タイトルをクリックしてファイルのダウンロードができるように、HTML式として以下を記述します。
<a href="&G_DOWNLOAD_URL.#ID#&session=&APP_SESSION.">#TITLE#</a>

検索ファセットのデフォルトはRow Searchになっています。Row Searchの代わりにOracle Textを使うこともできます。
ファセットP5_SEARCHの設定の検索タイプをOracle Textに変更し、ソースのデータベース列をTITLEに限定します。列TITLEに作成した全文検索索引はユーザー・データストアを構成することにより、列TITLE、ABSTRACTそれとファイルの内容を元に作成されています。

以上でファセット検索のページは完成です。
ページを実行すると、先頭のGIF動画のように動作します。
今回作成したアプリケーションのエクスポートを以下に置きました。ファセット検索のページが追加されています。
https://github.com/ujnak/apexapps/blob/master/exports/simple-file-manager-tags.zip
APEX_STRING_UTIL.FIND_TAGSの問題
#で始まるタグが複数連続しているときに、1つの空白で分割されていると後続のタグが認識されません。空白が2つ以上あると複数のタグとして認識されます。
例えば、以下を実行すると結果は#日本だけになります。
select column_value from table(apex_string_util.find_tags('#日本 #北海道'));

空白が2つで分割されていると、#日本と#北海道になります。
select column_value from table(apex_string_util.find_tags('#日本 #北海道'));

空白の代わりにカンマで区切っても結果は同じです。
select column_value from table(apex_string_util.find_tags('#日本,#北海道'));
すでに開発元に報告済みの不具合のようです。
完