このアプリケーションのCohereを使った処理を、Llama.cppのOpenAI互換APIの呼び出しに変えてみます。Llama.cppでOpenAI互換APIを使用する方法については、
Llama2の7Bのモデルで生成されるベクトル埋め込みの次元は4096、13Bのモデルでは5120になります。Pineconeのインデックスは使用するモデルの次元数に合わせて作り直す必要があります。
改変したAPEXアプリケーションのエクスポートは以下です。
https://github.com/ujnak/apexapps/blob/master/exports/vector-documents-search-openai.zip
知識として以下の4行を登録します。
「上野動物園では、アジアゾウのウタイとアルンの母子とスーリヤの3頭が飼育されています。」
「多摩動物公園ではアヌーラ、アマラ、ビィドゥラの3頭のスリランカゾウとアフリカゾウのトムの1頭が飼育されています。」
「横浜動物園ズーラシアではラスクマルとシュリーの2頭のアジアゾウが飼育されています。」
「金沢動物園ではボンとヨーコの2頭のインドゾウが飼育されています。」
アプリケーションはファイルのアップロードだけではなく、知識を直接フォームから登録できるように改変しています。
アップロードするファイルもPDFではなく、セパレータとして'---'または'==='を含めたプレーンテキストの文書を受け付けるように変更しています。
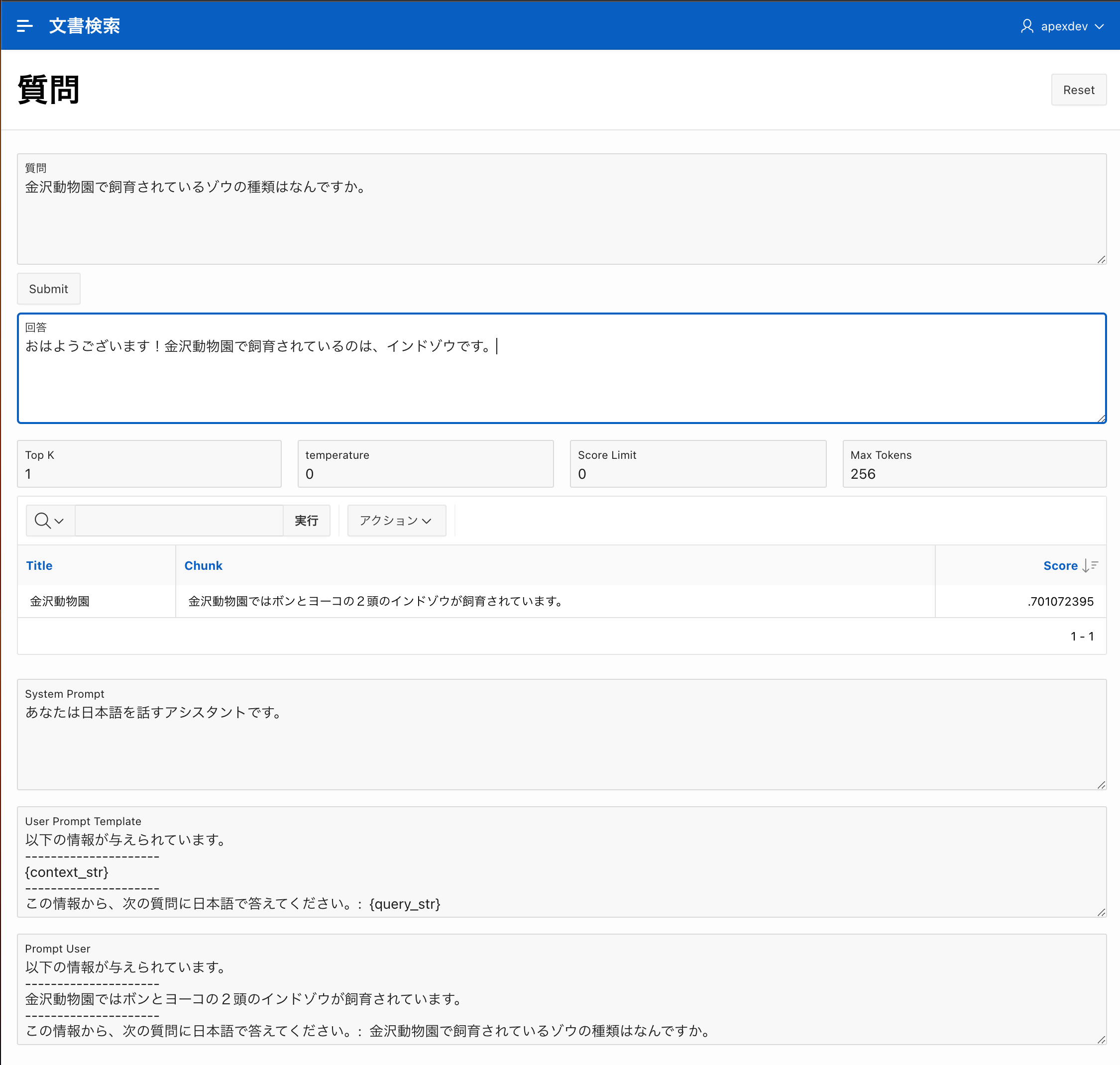
質問を実行してみます。
質問:「金沢動物園で飼育されているゾウの種類はなんですか。」
回答:「おはようございます!金沢動物園で飼育されているのは、インドゾウです。」
APIのリクエストに含めるmessagesとして、roleがsystemであるcontentとroleがuserであるcontentを含めるようにしています。
roleがsystemのcontentとして、ページ・アイテムP3_PROMPT_SYSTEMに入力した文章をそのまま使用します。roleがuserのcontentとして、ページ・アイテムP3_PROMPT_TEMPLATEに記述されたテンプレートの{context_str}の部分をインデックスの検索結果として得られた知識(チャンク)で置き換え、そして、{query_str}の部分を質問で置き換えた文章を使用します。
ページ・アイテムP3_PROMPT_SYSTEMは、以下をデフォルトとして設定しています。
あなたは日本語を話すアシスタントです。
ページ・アイテムP3_PROMPT_TEMPLATEは、以下をデフォルトとして設定しています。
以下の情報が与えられています。
---------------------
{context_str}
---------------------
この情報から、次の質問に答えてください。: {query_str}
APEXのアプリケーションから質問を行うと、Llama.cppからは以下のログが出力されます。
llama_print_timings: load time = 24694.52 ms
llama_print_timings: sample time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
llama_print_timings: prompt eval time = 11806.55 ms / 34 tokens ( 347.25 ms per token, 2.88 tokens per second)
llama_print_timings: eval time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
llama_print_timings: total time = 11895.69 ms
INFO: ::1:39706 - "POST /v1/embeddings HTTP/1.0" 200 OK
Llama.generate: prefix-match hit
llama_print_timings: load time = 24694.52 ms
llama_print_timings: sample time = 40.99 ms / 41 runs ( 1.00 ms per token, 1000.22 tokens per second)
llama_print_timings: prompt eval time = 55983.91 ms / 162 tokens ( 345.58 ms per token, 2.89 tokens per second)
llama_print_timings: eval time = 15736.55 ms / 40 runs ( 393.41 ms per token, 2.54 tokens per second)
llama_print_timings: total time = 72299.14 ms
INFO: 150.136.133.92:0 - "POST /v1/chat/completions HTTP/1.0" 200 OK
質問文のベクトル埋め込みの計算(POST /v1/embeddings)で、約12秒、回答の生成(POST /v1/chat/completions)に72秒程度の時間がかかっています。非常に簡単な質問でこの程度の処理時間なので、長文はほぼ扱えません。
次の質問です。
質問:「金沢動物園で飼育されているアジアゾウの名前を教えてください。」
回答:「はい、すみません。金沢動物園で飼育されているアジアゾウの名前は「ボン」と「ヨーコ」です。」
正解に見えます。
次の質問です。
質問:「多摩動物公園で飼育されているアジアゾウの名前を教えてください。」
回答:「はい、あなたに答えます。多摩動物公園で飼育されているアジアゾウの名前は、アヌーラです。」
多摩動物公園にはアヌーラの他にアマラとビィドゥラが飼育されていますが、必ずしも不正解とは言えないでしょう。
質問を変えてみます。「すべて」を追加しました。
質問:「多摩動物公園で飼育されているアジアゾウの名前をすべて教えてください。」
回答:「はい、あなたに答えます。以下のように、多摩動物公園で飼育されているアジアゾウの名前は、アヌーラ、アマラ、ビィドゥラ、トムです。」
回答にアフリカゾウのトムが含まれているため、不正解です。
以下の質問をしてみます。知識は不要なので、テンプレートを変更し{query_str}のみを記載します。
質問:「インドゾウとスリランカゾウとアフリカゾウのうち、アジアゾウに含まれるゾウはどれですか?」
回答:「アジアゾウに含まれるゾウは、インドゾウとスリランカゾウの2種類です。」
正解です。知識としてはあるのかもしれません。質問のテンプレートを以下に変更し、同じ質問をしてみます。
以下の情報が与えられています。
---------------------
{context_str}
アジアゾウに含まれるゾウは、インドゾウとスリランカゾウの2種類です。アジアゾウにアフリカゾウは含まれません。
---------------------
この情報から、次の質問に日本語で答えてください。: {query_str}
回答:「はい、あなたに答えます。以下が多摩動物公園で飼育されているアジアゾウの名前です。
* アヌーラ
* アマラ
* ビィドゥラ
私たちは、スリランカゾウとアフリカゾウを飼育していません。」
トムは除かれましたが、最後に正しくない回答が加わっています。
以下の質問は回答が間違っています。
質問:「アジアゾウのアルンが飼育されている動物園を教えてください。」
回答:「あなたは、多摩動物公園でアジアゾウのアルンが飼育されています。」
Pineconeのインデックスを検索したときにTop Kとして1を与えていて、以下の知識だけがプロンプトに含まれました。
「多摩動物公園ではアヌーラ、アマラ、ビィドゥラの3頭のスリランカゾウとアフリカゾウのトムの1頭が飼育されています。」
まったく知識がない状態なので、適当な回答が生成されています。
Top Kを2にし、2番目に類似度が高い知識もプロンプトに含めてみました。2番目の知識に上野動物園の情報が含まれたので、正解に見える回答が得られています。
回答:「はい、わかりました。アジアゾウのアルンは上野動物園で飼育されています。」
少し質問を変えてみます。Top Kに2を指定します。
質問:「アルンのお母さんのゾウの名前を教えてください。」
回答:「はい、わかりました。アルンのお母さんのゾウの名前はスーリヤです。」
間違っています。知識として与えている文章が認識できてないようです。知識の方を以下の文章に変更します。
「上野動物園では、アジアゾウのアルンとその母のウタイ、その他にスーリヤの3頭が飼育されています。」
同じ質問をします。
回答:「はい、わかりました。アルンのお母さんのゾウの名前は「ウタイ」です。」
正解です。
実用できるかどうかの判断は、OpenAIのAPIやLlama2でも70Bのモデルを使って行なう必要があると思いますが、なかなか一筋縄ではいかないように感じます。
以下より、以前のアプリケーションからの変更点を説明します。
表定義ですが、表KB_CHUNKSの列SPLIT_CHARをSPLIT_CHARSに変更し、VARCHAR2(1)からVARCHAR2(8)に変更しています。その他、長い文字列を保存する列の型をVARCHAR2(4000)からCLOBに変更しています。
OpenAI互換のAPIを呼び出すように改変したパッケージKB_LLM_UTILのコードは以下になります。
アプリケーション定義の置換のセクションで、G_INDEXにPineconeのインデックス、G_ENDPOINTにOpenAI互換APIを呼び出すエンドポイント(OpenAIであればhttps://api.openai.com)を設定します。
Pineconeのインデックス操作に使用する
Web資格証明と、(OpenAIのAPIを呼び出す場合は)
OpenAIのAPIを呼び出す際に使用する
Web資格証明を作成しておきます。
パッケージKB_LLM_UTILのプロシージャで、Pineconeにアクセスするものには引数p_pinecode_cred、OpenAIのAPIアクセスを行なうものは引数p_cred_idを持っています。
それぞれパラメータを選択し、値に作成したWeb資格証明の静的IDを設定します。
roleがsystemのメッセージのデフォルトは、ページ・アイテムP3_PROMPT_SYSTEMに設定されています。
roleがuserのメッセージを作るテンプレートは、ページ・アイテムP3_PROMPT_TEMPLATEに設定されています。
Llama2の処理に時間がかかるため、デフォルトの状態だとNginxでタイムアウトが発生します。server.confを以下に変更し、プロキシ関連のタイムアウトを6分に延長します。
アプリケーションの変更点は以上になります。
Oracle APEXのアプリケーション作成の参考になれば幸いです。
完