OpenAIのChatGPTでIn-context Learningを実装するために、LlamaIndexがよく使われているようです。本ブログでも以前に記事として取り上げたことがあります。
LlamaIndexは色々な外部連携の手段(Data Connectorsや各種のIndexesなど)を提供しています。それらを活用するには、基本Pythonでのコーディングとなり、ほとんどOracle APEXの出番はありません。Oracle APEXでアプリケーションを作る方にPythonが得意な方が多いとは思いませんし、また、SQL、PL/SQL、JavaScript、HTMLにCSSと覚えて、さらにPythonとなると、かなり大変です。
LlamaIndexの仕組みを勉強して、似たような処理を行なうAPEXアプリケーションを作ってみました。以下の記事よりLlamaIndexについて勉強させていただきました。
DeveloperIOの記事より
LlamaIndexを完全に理解するチュートリアル その1:処理の概念や流れを理解する基礎編(v0.6.8対応)以下のGIF動画のように、APEXアプリにファイルをアップロードします。ファイルをアップロードする際に、以下の処理を実施しています。
- アップロードされたファイルからOracle TextのAuto Filterを使って文字列を抽出する。
- 抽出した文字列を、それより小さなチャンクに分割する。
- 分割したチャンクごとにCohereのEmbed APIを呼び出してベクトル埋め込みを生成する。
- 生成したベクトル埋め込みをPineconeのインデックスに保存する。
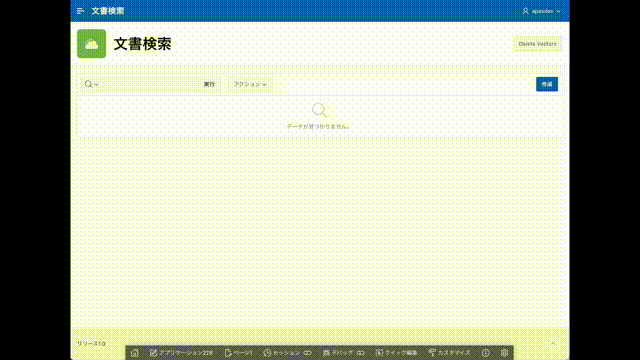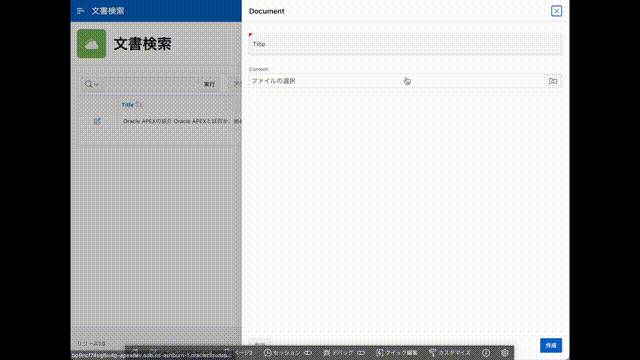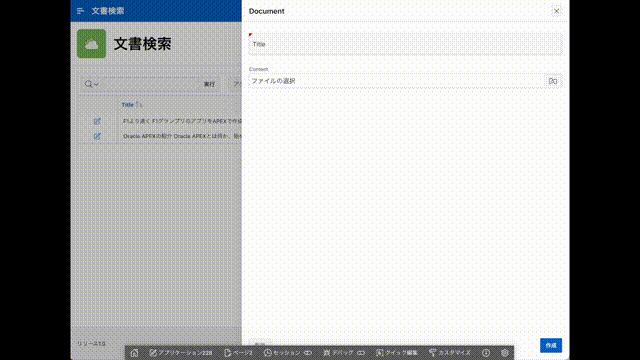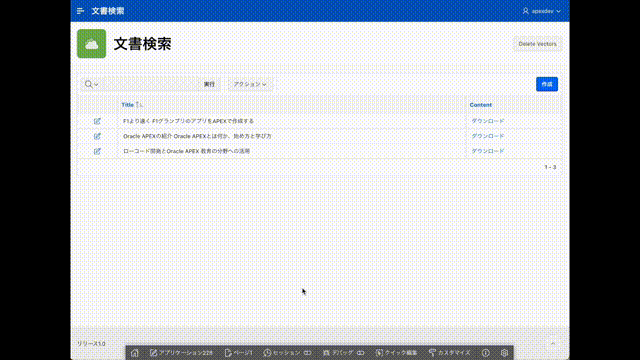
Pineconeのインデックスを確認すると、3つのドキュメントのアップロードにより1726のベクトルが保存されていることがわかります。

質問を行います。アップロードしたファイルの内容を参照します。質問の際には以下の処理を実行します。
- 質問の文字列からベクトル埋め込みを生成する。
- Pineconeのインデックスを質問のベクトル埋め込みで検索し、類似したチャンクをいくつか取り出す。
- 質問と取り出されたチャンクよりプロンプトを作成し、CohereのGenerate APIを呼び出す。
- CohereのGenerate APIの応答を回答とする。

CohereのGenerate APIのリファレンスには(Summarizeと異なり)英語のみとは書かれていません。しかし、日本語による回答は文書になっていないことが多いです。結果として英語でないとAPIの回答を評価できません。
Cohereの代わりにOpenAIを使用する場合は、ベクトル埋め込み(embedding)を生成するAPIと、そのモデルとしてtext-embedding-ada-002が使用できます。この場合はインデックスの次元は1536になります。また、回答の生成にはChat Completion APIを使用します。
上記のアプリケーションのエクスポートを以下に置きました。
https://github.com/ujnak/apexapps/blob/master/exports/vector-documents-search.zip
これより、簡単に実装について説明します。
表の作成
クイックSQLの以下のモデルから、アプリケーションで使用する表を作成します。

以下の5つの表を作成しています。
- KB_DOCUMENTS - アップロードしたファイルを列CONTENT(BLOB形式)に保存し、それより抽出した文字列を列CONTENT_TEXT(CLOB形式)に保存する。CONTENTから文字列の抽出に失敗したときは、IS_FAILEDにYを立てる。
- KB_CHUNKS - KB_DOCUMENTSのCONTENT_TEXTの内容をより小さなチャンクに分割し、列CHUNKに保存する。チャンクより生成したベクトル埋め込みを列EMBEDDINGに保存する。ベクトル・データベースに保存済みであれば、IS_INDEXEDにYを立てる。
- KB_QUESTIONS - 入力した質問を列QUESTIONに保存する。質問の文字列から生成したベクトル埋め込みを列EMBEDDINGに保存する。
- KB_ANSWERS - 質問のベクトル埋め込みより、インデックスを検索する。検索結果として返されるID(チャンクのベクトル埋め込みをインデックスに保存する際、KB_CHUNKSのIDをベクトルのIDとしている)とSCOREを列CHUNK_IDとSCOREに保存する。
- KB_RESPONSES - 質問とインデックスの検索結果より得られたチャンクを使ってプロンプトを生成する。生成したプロンプトを列PROMPTに保存し、LLMのAPIを呼び出して得られた回答をGENERATED_ANSWERに保存する。今のところCohereではChat形式のAPIは提供されていないので、ITERATIONは常に1になる。繰り返し問い合わせることで回答をRefineできる場合は、このITERATIONが増える。
このアプリケーションが使用する表の説明は以上です。
パッケージの作成
ほとんどの処理はパッケージKB_LLM_UTILに実装しています。パッケージのコードは以下です。
以下の6つのプロシージャを含んでいます。
- APPLY_AUTO_FILTER - ファイルから文字列を抽出する。
- SPLIT_INTO_CHUNKS - 抽出した文字列をチャンクに分割する。
- GENERATE_EMBEDDINGS - チャンクのベクトル埋め込みを生成する。
- UPSERT_VECTORS - チャンクのベクトル埋め込みをベクトル・データベースのインデックスに保存する。
- ASK - 質問を受け付け、インデックスを検索する。質問と検索結果のチャンクより、生成AIのAPIを呼び出し回答を生成する。
- DELETE_VECTORS - 指定した文書に紐づくベクトルをインデックスから削除する。
このプロシージャの中で、検索結果への影響が大きいプロシージャはSPLIT_INTO_CHUNKSとASKです。SPLIT_INTO_CHUNKSにおいて、アップロードされたファイルの内容を、回答として意味があるような塊として分割することは非常に重要です。また、ASKでは、生成AIが適切な回答を返すようなプロンプトを生成する必要があります。
APEXアプリケーションの実装
アプリケーション作成ウィザードを起動し、ホーム・ページを削除し、代わりに表KB_DOCUMENTSをソースとしたフォーム付き対話モード・レポートのページを追加します。

対話モード・レポートのページの追加では、表またはビューとしてKB_DOCUMENTSを選択し、フォームを含めるにチェックを入れます。

表KB_DOCUMETNSにはBLOB型の列CONTENTが含まれます。APEXのアプリケーション作成ウィザード(およびページ作成ウィザード)は、BLOB列へのファイルのアップロード機能を自動で実装します。
ページ番号1の対話モード・レポートでは、CLOB型の列CONTENT_TEXTはデータが大きすぎて表示できません。アクション・メニューの列より、表示対象から除きます。

ページ・デザイナで対話モード・レポートのページを開き、列CONTENTのBLOB属性を設定します。MIMEタイプ列としてCONTENT_MIMETYPE、ファイル名列としてCONTENT_FILENAME、最終更新列としてCONTENT_LASTUPD、文字セット列としてCONTENT_CHARSETを設定します。
これらの列は、クイックSQLのモデルにデータ型としてfileを指定すると、自動的に生成されます。


ファイルの作成、更新、削除と同時に、ベクトル・データベースも更新するようにプロセスを追加します。
プロセス・ビューを開きます。アプリケーション作成ウィザードによって、プロセスプロセス・フォームDocumentとダイアログを閉じるが作成されています。

プロセスベクトルの削除は、プロレス・フォームDocumentより上の配置します。サーバー側の条件のタイプにリクエストは値に含まれるを選択し、値にSAVE,DELETEを指定します。ファイルの更新(変更の適用をクリックしたとき)では、既存のファイルより生成されたベクトルを最初に削除した上で、新規ファイルと同じ手順で作成されたベクトルで置き換えます。
パッケージ・プロシージャのKB_LLM_UTIL.DELETE_VECTORSを呼び出します。
パラメータp_idには、表KB_DOCUMENTSの主キーであるページ・アイテムP3_IDが設定されます。パラメータp_indexには置換文字列のG_INDEX、p_pinecone_credはPineconeにアクセスするためのWeb資格証明を設定します。

ファイルのアップロード後に実行されるベクトル・データベースへのベクトルの保存を行なう一連のプロセスは、実行チェーンを使ってまとめます。
識別の名前を索引作成、タイプに実行チェーンを選択します。設定のバックグラウンドの実行はオフにします。一連の処理は時間がかかるため、設定のバックグラウンド実行をオンに変えるとブラウザの反応が良くなります。ただし、CohereのAPIの無料枠に設けられているレート制限にかかる可能性があります。
プロセステキストの抽出では、パッケージ・プロシージャKB_LLM_UTIL.APPLY_AUTO_FILTERを呼び出します。


プロセスベクトル埋め込みの生成では、パッケージ・プロシージャKB_LLM_UTIL.GENERATE_EMBEDDINGSを呼び出します。


以上で、ファイルをアップロードすると、テキストの抽出、チャンクへの分割、ベクトル埋め込みの生成、インデックスへのUpsertが順次実施されます。
検索ページの作成
空白のページを作成します。ページ・アイテムやリージョンを作成し、以下のように配置します。

ページ・アイテムP3_PROMPT_TYPEは、Cohere Generate APIに渡すpromptの形式を指定します。タイプは選択リストです。

選択肢として、質問のみをQ、質問が後 - スコア昇順をA、質問が前 - スコア降順をBとして定義します。

ページ・アイテムP3_QUESTIONに質問を入力します。タイプはテキスト領域です。

ボタンSUBMITをクリックすると、質問文からのベクトル埋め込みの生成、インデックスの検索、プロンプトの作成とCohere Generate APIの呼び出し、といった一連の処理を実行します。


ページ・アイテムP3_TOP_K、P3_TEMPERATURE、P3_SCORE_LIMIT、P3_MAX_TOKENSのタイプは数値フィールドで、主にAPI呼び出しに指定するパラメータを与えます。
P3_TOP_KはPineconeのquery APIの引数topKに渡されます。ここで指定した数だけ質問文に類似したチャンクが返されます。P3_TEMPERATUREはCohere Generate APIの引数temperatureに渡されます。0から5の間の値になります。低い値であるほど、揺らぎの少ない回答が得られます。P3_SCORE_LIMITはAPIへの引数ではなく、Pineconeのインデックスの検索結果から、これ以下のスコアのチャンクはプロンプトに含めないように制限します。P3_MAX_TOKENSはCohere Generate APIの引数max_tokensに渡されます。

リージョンanswerは、Pineconeのインデックスの検索結果を表示する対話モード・レポートです。ソースのSQL問合わせは以下になります。
select a.ID,
a.QUESTION_ID,
d.TITLE,
c.CHUNK,
a.SCORE,
a.ANSWERED_DATE
from KB_ANSWERS a
join KB_CHUNKS c on a.chunk_id = c.id
join KB_DOCUMENTS d on d.id = c.document_id
where a.question_id = :P3_QUESTION_ID
ページ・アイテムP3_QUESTION_IDは、質問を保持する表KB_QUESTIONSの主キーであるQUESTION_IDの値を保持します。タイプは非表示です。

ページ・アイテムP3_PROMPTは、Cohere Generate APIに渡されたpromptを表示します。回答の元になったプロンプトを確認するために使用します。タイプはテキスト領域です。

パッケージ・プロシージャKB_LLM_UTIL.ASKを呼び出します。パラメータはページ・アイテムに割り当てられているか、または、APIデフォルトです。

APEXアプリケーションの説明は以上になります。
実際にアプリケーションを作成して、いくつか感じたことを列挙しておきます。
- 現状、Cohereで日本語を扱うのは難しい印象。
- LlamaIndexでもデフォルトではResponse Synthesizerは凝ったことはしていない模様。なので、ここ(プロシージャKB_LLM_UTIL.ASK)がカスタマイズのポイントでは無さそう。
- チャンクへの分割が重要。一塊の説明をチャンクにする必要があるが、実装は難しそう。OpenAIのAPI呼び出しでチャンクに分割できれば、それが一番簡単で精度が高いのではないか。
- Oracle TextのAuto Filterの適用は失敗することがあり、IS_FAILED列の確認は必要。
Oracle APEXのアプリケーション作成の参考になれば幸いです。
完