AppleのMシリーズのMacbookにLM Studioをインストールして、 ローカル・サーバー(Local Inference Server)を実行してみます。OpenAI互換のChat Completions APIを呼び出すOracle APEXアプリケーションから、このローカル・サーバーを呼び出しLLMとチャットを行います。
以下のようにAPEXアプリケーションよりChat Completions APIを発行し、LM Studioのローカル・サーバーで処理を行います。

ELYZA-japanese-Llama-2-7b-fast-instruct-q8_0.ggufをロードしてみます。使用できるメモリが少ない場合は、低いビット数で量子化されたモデルを選ぶと良いでしょう。
LM Studioをインストールして起動した状態から、作業を始めます。
検索(Search)画面を開き、検索ボックスからELYZAを検索します。検索結果より
ELYZA-japanese-Llama-2-7b-fast-instruct-q8_0.ggufをダウンロードします。


ローカル・サーバー(Local Server)の画面を開きます。



http://localhost:8080/v1/chat/completions


OpenAIのChat Completions APIを呼び出すAPEXアプリを作成する
https://apexugj.blogspot.com/2024/04/chat-with-generative-ai-sample-app-0.html
SQLワークショップのSQLスクリプトより、作成を実行します。








アプリケーション定義の編集を開きます。



ワークスペースに作成されている唯一のユーザーapexdevにて、アプリケーションにサインインします。
検索(Search)画面を開き、検索ボックスからELYZAを検索します。検索結果より
ELYZA-japanese-Llama-2-7b-fast-instruct-q8_0.ggufをダウンロードします。

ダウンロードされたら、モデル(My Models)の画面を開き、ダウンロードされたモデルがあることを確認します。


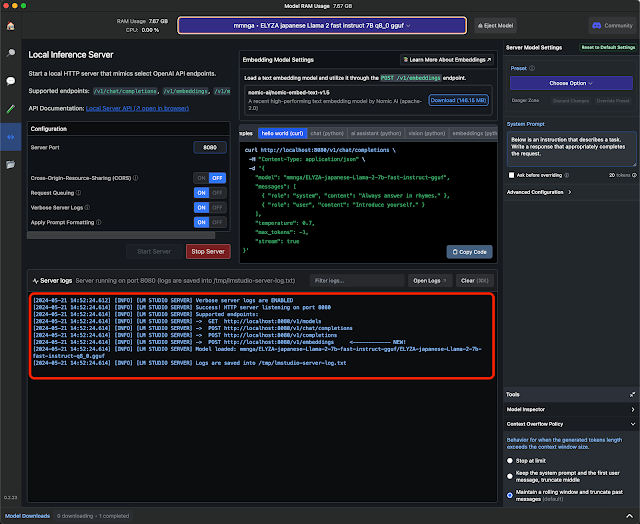
ローカル・サーバーの構成を指定します。
Server Portは8080とします。すでにポートが使用中であれば違う番号にします。Cross-Origin-Resource-Sharing(CORS)はOFF、Request Queuing、Verbose Server Logs、Apply Prompt FormattingはONとします。

画面上部のSelect a model to loadをクリックし、ダウンロード済みのモデルELYZA japanese Llama 2 fast instructを選択します。

モデルがロードされるとローカル・サーバーが起動します。
OpenAI互換のChat Completions APIは以下のURLより呼び出すことができます。
http://localhost:8080/v1/chat/completions

OpenAI互換のサーバーが起動したので、Oracle APEXの準備に移ります。
macOSでのOracle APEXの構成手順は、以下の記事にまとめられています。
単一のデータベース・コンテナだけで構成する手順は「podmanを使ってOracle Database FreeとOracle REST Data Servicesをコンテナとして実行する」、データベースとORDSのコンテナで構成する手順は「podmanを使ってOracle Database FreeとOracle REST Data Servicesをコンテナとして実行する」です。
Oracle APEX 24.1.0では、LM StudioのAPIを呼び出すためにAPEX_WEB_SERVICE.MAKE_REST_REQUESTを実行するとORA-1841が発生しました。Oracle APEX 24.1.5のパッチを適用することにより、エラーは解消しました。
Oracle APEXのパッチは、以下のリンクより参照できます。
ワークスペースも続けて作成します。手順についてはこちらの記事「APEXのワークスペースを作成するコードを記述する」で紹介しているcreate_workspace.sqlを実行します。
作成したワークスペースにサインインします。本記事ではワークスペースはapexdev、ユーザーはapexdevとして作成しています。

Oracle APEXの開発画面が開きます。

これからは、以下の記事で作成しているAPEXアプリケーションをインストールします。
https://apexugj.blogspot.com/2024/04/chat-with-generative-ai-sample-app-0.html
OpenAIのChat Completions APIを呼び出すパッケージUTL_OPENAI_CHAT_APIは、表OPENAI_TOOLSを参照するため、あらかじめ表OPENAI_TOOLSを作成します。
SQLワークショップのSQLスクリプトより、作成を実行します。

実行するスクリプトを貼り付け、スクリプト名を入力して実行します。

スクリプトは即時実行します。

表OPENAI_TOOLSが作成されます。

同様の手順にて、パッケージUTL_OPENAI_CHAT_APIのパッケージ定義部と本体を作成します。
パッケージ定義
パッケージ本体
エクスポートされたAPEXアプリケーションをダウンロードし、ワークスペースにインポートします。
https://github.com/ujnak/apexapps/blob/master/exports/chat-with-generative-ai-0.zip
アプリケーション・ビルダーからインポートを実行します。
https://github.com/ujnak/apexapps/blob/master/exports/chat-with-generative-ai-0.zip
アプリケーション・ビルダーからインポートを実行します。

インポートするファイルとしてchat-with-generative-ai-0.zipを選択します。
次へ進みます。

アプリケーションのインストールを実行します。

アプリケーションがインポートされました。
接続先となるLLMを設定するため、アプリケーションの編集を実行します。

アプリケーションの編集画面が開きます。

アプリケーション定義の置換タブを開きます。
置換文字列のG_API_ENDPOINTの置換値は以下です。
http://host.containers.internal:8080/v1/chat/completions
置換文字列G_CREDENTIALの置換値は空白にします。G_MODEL_NAMEにはローカル・サーバーにロードしたモデルmmnga/ELYZA-japanese-Llama-2-7b-fast-instruct-gguf/ELYZA-japanese-Llama-2-7b-fast-instruct-q8_0.ggufを設定します。

変更を適用し、アプリケーションを実行します。



User Messageに「東京から大阪まで一番早く着く方法と、その時間を教えてください。」と入力し、Send Messageをクリックします。

内容はさておき、日本語としては正確な回答が得られます。

LM StudioのトップページにMade possible thanks to the llama.cpp project.との記載があるため、LLMの処理にはllama.cppの実装が使われている模様です。
LM Studioを使うとllama.cppをそのまま使用するより、はるかに簡単にローカル・サーバーを立てることができます。
今回の記事は以上になります。
完