テキストの取り出しとチャンク分割を行うファイルをアプリケーションにアップロードし、DBMS_VECTOR_CHAINのUTL_TO_TEXTおよびUTL_TO_CHUNKSを呼び出します。UTL_TO_TEXTについては指定可能なパラメータが少ないため、plaintextおよびcharsetをそれぞれ指定できるようにしています。UTL_TO_CHUNKSは色々なパラメータを指定できるため、パラメータをJSONのまま与えるようにしています。
指定できるパラメータについては23aiのSQL Language Referenceの、VECTOR_CHUNKSで説明されています。
https://github.com/ujnak/apexapps/blob/master/exports/sample-dbms-vector-chain.zip
以下にアプリケーションの実装のポイントを紹介します。
テキストの取り出しおよびチャンク分割の対象とするファイルを選択するページ・アイテムはP1_FILEとして作成しています。ページ・アイテムのタイプはファイルのアップロードです。
ストレージのタイプに表APEX_APPLICATION_TEMP_FILESを選択し、ファイルをパージするタイミングはリクエストの終わりとしています。アップロードしたファイルからテキストが取り出し、ページ・アイテムP1_TEXTに保存します。その後はアップロードしたファイルを参照することはないため、リクエストが終了した時点でファイルはパージします。

UTL_TO_TEXTのパラメータのひとつであるplaintextを設定するページ・アイテムをP1_PLAINTEXTとして作成しています。指定可能な値はtrueまたはfalseなので、ページ・アイテムのタイプに切替えを選択しています。
設定のデフォルトの使用をオフにし、オン値にtrue、オフ値にfalseとしています。デフォルトはtrueです。

UTL_TO_TEXTに与えることができるもうひとつのパラメータであるcharsetは、ページ・アイテムP1_CHARSETで指定します。ただし、このパラメータはUTF8以外受け取らないため、タイプをテキスト・フィールド、デフォルトをUTF8としています。


UTL_TO_TEXTを呼び出すボタンTO_TEXTを作成しています。動作のアクションはページの送信です。

ボタンTO_TEXTを押したときに実行されるプロセスをUTL_TO_TEXTとして作成しています。
実行するコードは以下です。DBMS_VECTOR_CHAIN.UTL_TO_TEXTを呼び出しています。ドキュメントのExampleでは、"plaintext": "true" との指定が記述されていますが、このコードでは"plaintext": true (文字列ではなくboolean)としています。

UTL_TO_CHUNKSの呼び出しの際に与えるパラメータを指定するページ・アイテムをP1_PARAMSとして作成しています。ページ・アイテムのタイプをテキスト領域とし、JSONを記述するようにしています。

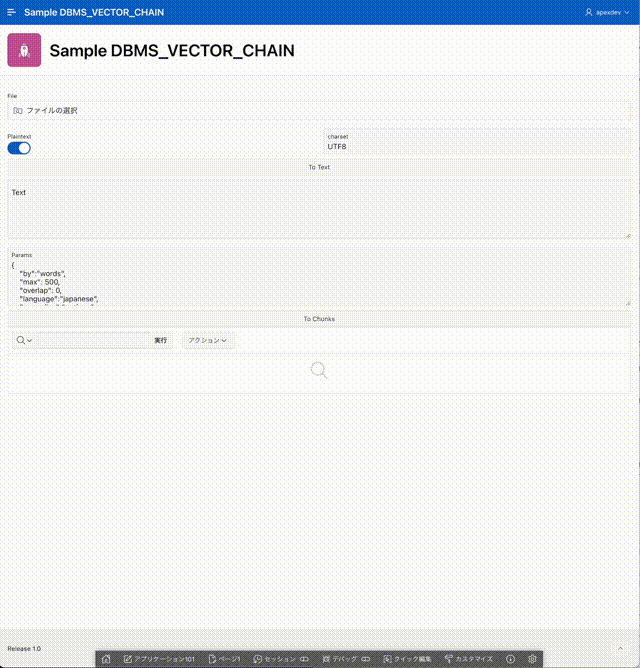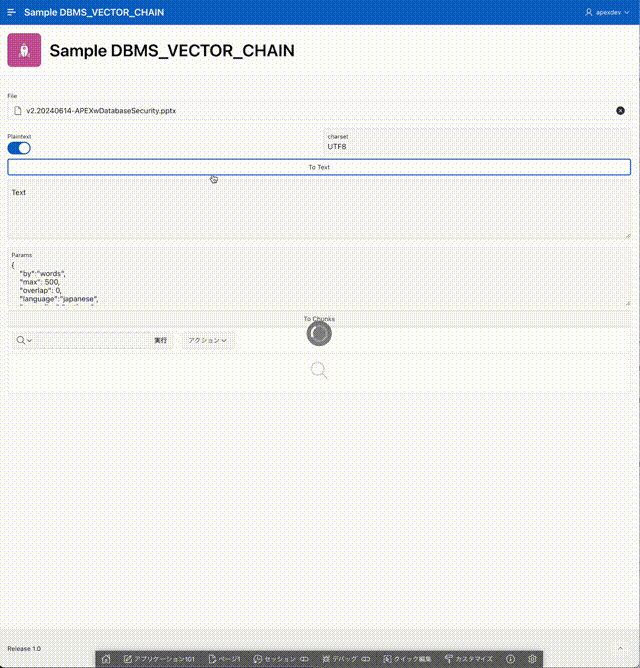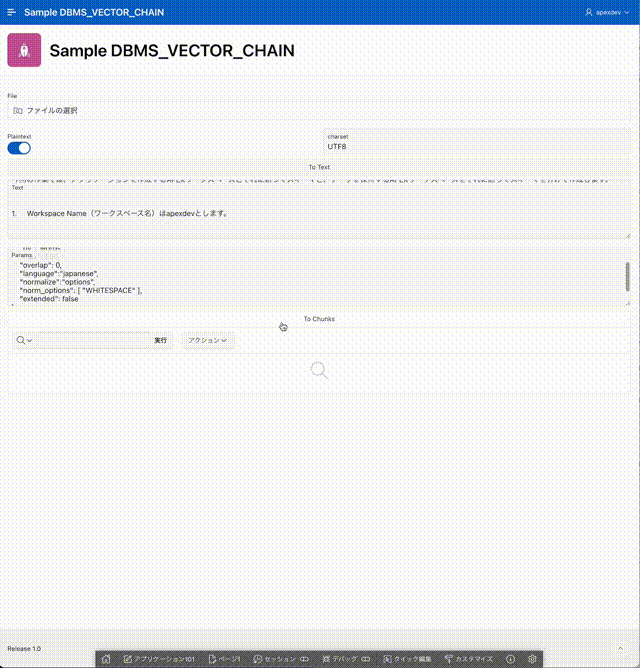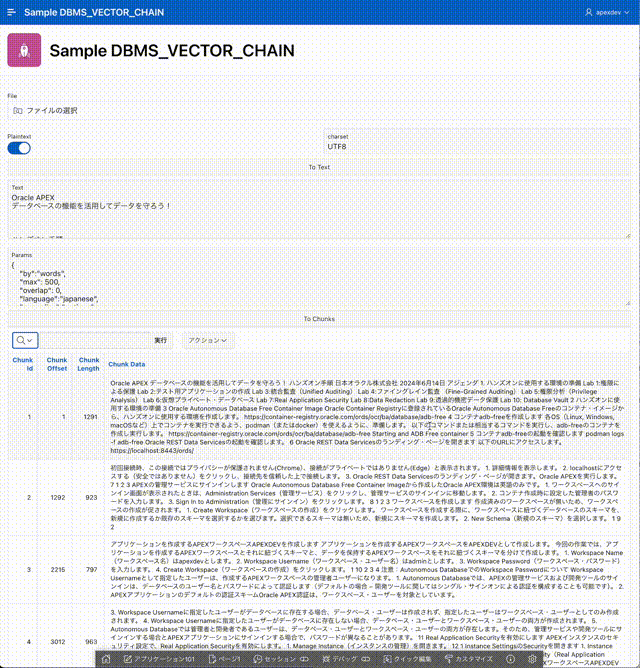
UTL_TO_CHUNKSを呼び出し分割されたチャンクは、対話モード・レポートで表示します。チャンク自体はAPEXコレクションに保存します。
リージョンのソースとして以下のSQLを記述します。
select
n001 chunk_id, n002 chunk_offset, n003 chunk_length
,clob001 chunk_data
from apex_collections where collection_name = 'CHUNKS' 
UTL_TO_CHUNKSを呼び出すボタンTO_CHUNKSを作成しています。動作のアクションはページの送信です。

ボタンTO_CHUNKSを押したときに実行されるプロセスをUTL_TO_CHUNKSとして作成しています。
実行するコードは以下です。DBMS_VECTOR_CHAIN.UTL_TO_CHUNKSを呼び出しています。ドキュメントのExampleでは、"max": "100", "overlap":"0" との指定が記述されていますが、本来は"max": 100, "overlap": 0(文字列ではなく数値)ではないかと思います。

アプリケーションの実装の紹介は以上です。
PowerPointやPDFのファイルを対象にテキスト取り出しとチャンク分割を行なってみましたが、設定によっては「ORA-20000: Oracle Textエラー: DRG-50857: oracle error in dbms_vector_chain.utl_to_chunks ORA-06502: PL/SQL: 値または変換エラー: Bulk Bind: Truncated Bindが発生しました」というエラーが発生しました。

VECTOR_CHUNKSでは、データベースの初期化パラメータのmax_string_sizeがextendedの場合は、チャンクのバイト長が32767に拡張されるとの説明があります。これはVECTOR_CHUNKSの場合に限定されていてDBMS_VECTOR_CHAIN.UTL_TO_CHUNKSには適用されないようです。UTL_TO_CHUNKSの戻り値のタイプであるVECTOR_ARRAY_Tの要素のJSONとして"chunk_data":"VARCHAR2(4000)"と記載されていて、max_string_sizeがextendedでも32767に拡張されないようです。
DBMS_VECTOR_CHAIN.UTL_TO_CHUNKSをVECTOR_CHUNKSに書き直すと、以下のようなコードになります。chunk_specは文字列として指定する必要があります。
VECTOR_CHUNKSの呼び出しではチャンクの長さが4000バイトを超えても「ORA-06502: PL/SQL: 値または変換エラー: Bulk Bind: Truncated Bindが発生しました」のエラーは発生しません。
今回の記事は以上になります。
Oracle APEXのアプリケーション作成の参考になれば幸いです。
完